Систематическая ошибка - ошибка исследования, не связанная с выборкой. Она может быть вызвана концептуальными или логическими ошибками, неправильной интерпретацией ответов, а также статистическими, арифметическими, табуляционными, кодовыми или отчетными ошибками.Систематические ошибки подразделяется на: случайные(дают оценки, отличные от истинного значения; они могут приводить к отклонениям и в большую, и в меньшую сторону и имеют при этом случайный характер) и неслучайные(приводят к односторонним отклонениям, для них характерна тенденция к смещению выборочного значения относительно параметра совокупности). Недостатки систематических ошибок: - не так часты, но и не настолько подконтрольны, как ошибки в выборке;- в систематических ошибках, как направление, так и величина ошибки могут оказаться совершенно непредсказуемыми, в отличие от выборок, где ошибки в выборке при использовании вероятностных методов могут быть оценены; - приводят к смещению выборочного значения относительно параметра совокупности;- влияют на достоверность выборочных оценок. Особенно критичными ошибки становятся при работе с широкомасштабными, хорошо продуманными вероятностными выборками, т.к. при увеличении эффективности проектирования выборки и уменьшении выборочной дисперсии, эффект систематических ошибок усиливается. Чем эффективнее составлена выборка, тем большую роль играют систематические ошибки и тем меньшим смыслом обладают вычисления по определению доверительного интервала, в основе которых лежат обычные формулы. Систематические ошибки делятся на два основных типа: ошибки, связанные с неполучением данных (ошибки ненаблюдения), и ошибки наблюдения. Ошибки ненаблюдения возникают вследствие невозможности получения данных от части элементов обследуемой совокупности и быть вызваны тем, что часть обследуемой совокупности не была представлена в выборке, или же элементы, отобранные для включения в выборку, не представили данных. Ошибки наблюдений возникают вследствие некорректной информации, полученной от элементов выборки, они могут возникнуть и на стадии обработки данных или формулирования итогового вывода.
48.Понятие и сущность ошибок ненаблюдения. Существуют два типа ошибок ненаблюдения: ошибки неохвата( систематическая ошибка, являющаяся следствием того, что определенные части или целые блоки генеральной совокупности не были включены в основу выборки) и ошибки неполучения данных. Неохват может стать источником серьезных неточностей, при этом ошибка неохвата относится только к ошибочно выпавшим из рассмотрения частям совокупности. Таким образом, проблема неохвата имеет отношение к основе выборки.Ошибка перебора может возникать из-за возникновения повторов в сводке элементов выборки.Ошибки неохвата:1) относятся к разряду систематических ошибок и потому не входят в стандартные стат. зависимос. ;2) как правило, не могут быть устранены посредством увеличения объема выборки;3) могут иметь существенный размер;4) могут быть уменьшены при осознании их наличия с помощью улучшения основы выборки и принятия ряда специальных мер, позволяющих до определенной степени компенсировать остаточное несовершенство основы. Ошибка неполучения данных – систематическая ошибка, порождаемая отсутствием информации о некоторых элементах, которые должны были войти в состав выборки. Для того, чтобы оптимизировать и стандартизировать практику исследований предлагается определение доли ответивших(отношение количества проведенных с респондентами интервью к количеству приемлемых респондентов в выборке). Различают две главные причины ошибки неполучения данных - это отсутствие и отказ от интервью. Отсутствие – систематическая ошибка, возник. вследствие неполучения ответов от заранее определенных респондентов, отсутствующих дома в момент звонка регистратора.Отказы от интервью – систематическая ошибка, возникающая вследствие того, что часть респондентов отказывается принимать участие в обследовании. Доля отказов зависит часто от особенностей респондентов, организаций, осуществляющих финансовое обеспечение обследования, обстоятельств контакта, темы обследования и искусства интервьюера.Стратегии, рекоменд. для корректировки ошибки:1. Увеличение доли первичных ответов (улучшение условий проведения интервью и углубленное обучение интервьюеров).2. Повторные попытки.3. Экстраполяция получ.информации(оценка возможного эффекта, обусловленного неполучением данных, и соответствующая коррекция результатов исследования).Частичное неполучение данных состоит в том, что респондент, согласившийся принять участие в опросе, не хочет или не может ответить на некоторые вопросы из-за специфики их формы или содерж. или вследствие нежелания обременять себя поиском инф.
49.Понятие и сущность ошибок наблюдения
Ошибка сбора – систематическая ошибка, возникающая при сборе данных.Человек отказ отвечать на одни и дает неправильные ответы на другие вопросы интервьюера - ошибками пропуска и ошибками свидетельства. Поведенческие факторы . Биографические данные, мнения, позиции, намерения респондента могут являться источниками ошибок. Существуют 3 модели поведения интервьюеров , которые приводят к появлению ошибок: ошибки при формулировке вопросов и неумение задавать уточняющие вопросы, ошибки при записи ответов, подтасовка данных.Достоверность:
1) Метод опроса - проверяется соответствие использованного метода заданному (например, действительно ли проводился персональный, а не телефонный опрос).
2) Поставленные вопросы - проверка того, не были ли выпущены из рассмотрения важные вопросы (демографического или классификационного характера).
3) Демонстрация продукции - проверка того, действительно ли была произведена потребная для проведения опроса демонстрация продукта или информационного листа.
4) Знакомство респондента с интервьюером - проверка того, не занимался ли интервьюер опросом своих знакомых или друзей.
5) Реакция на проведение опроса - проверка «качества» работы интервьюера.
Офисные ошибки . Систематические ошибки могут возникать не только при сборе информации. Они могут появляться при редактировании, кодировании, составлении таблиц и анализе данных.
Суммарные ошибки. Частные ошибки, складываясь, приводят к ошибке суммарной, которая и должна интересовать исследователей.
При работе с ошибками сбора данных можно воспользоваться схемой Кана- Кэннела
интервьюер респондент
Характеристики: Характеристики: теже что и у интер-ра
Возраст Психологические факторы:теже
Образование Поведенческие факторы:
Ответы на вопросы
(адекватные – неадекватные)
(точные – неточные)
Социально-экономический статус
Национальность,Религиозная принадлежность,Пол и т.д.
Психологические факторы: Восприятие,Позиция,Намерения,мотивы
Поведенческие факторы: Ошибки при вопросах,Ошибки при распределении типа респондентаОшибки мотивации,Ошибки при записи ответов
Личные особенности (характеристики). личные особенности могут серьезно повлиять на ответы. Психологические факторы . результаты работы интервьюеров имеют обусловленность их взглядами, позициями и стремлениями.
50.Редактирование данных. Редактирование включает в себя просмотр и, если необходимо, исправление каждой анкеты или формы регистрации наблюдений. Просмотр и внесение исправлений выполняются в 2 стадии: полевое редактирование и централизованное офисное редактирование.
Полевое редактирование - это предварительное редактирование, которое строится таким образом, чтобы обнаружить наиболее бросающиеся в глаза пропуски и неточности данных.
Оно также полезно для контроля поведения персонала полевых сил и внесения ясности. Полевое редактирование выполняется как можно скорее после того, как анкета заполнена. В этом случае проблемы могут быть устранены прежде, чем проводивший сбор информации будет расформирован. Полевое редактирование обычно выполняется руководителем полевых работ.
Централизованное офисное редактирование - всеобъемлющая проверка и коррекция заполненных форм сбора данных, включая принятие решения о том, что с этими данными делать.
Чтобы обеспечить логическую последовательность обработки материалов, лучше всего предоставить все носители собранных данных одному человеку. Если эту работу приходится делить по соображениям ее объема и имеющегося времени, подразделы должны определяться по частям анкеты, а не по респондентам. То есть, один редактор должен редактировать часть «А» всех анкет, а другой - часть «В».
В отличие от полевого, централизованное офисное редактирование в меньшей степенизависит от последующих процедур, и в большей - от степени полноты данных. При анализе необходимо решить, каким образом будут обрабатываться носители собранных данных, содержащие неполные ответы, явно неправильные ответы и ответы.
Вернувшиеся заполненные анкеты целиков. В некоторых окажутся пропущенными целые разделы. Другие будут оставленными без ответа отдельные позиции. Анкеты, в которых пропущены целые разделы, не должны отбрасываться автоматически. Тщательное редактирование анкеты иногда показывает, что ответ на какой-то вопрос очевидно неправилен.
При анализе необходимо не пропустить заполненные анкеты, которые неудачны с точки зрения интереса респондента. Свидетельства отсутствия интереса могут быть и очевидными, и очень трудно распознаваемыми.
51. Кодирование данных. Код-е – технический прием, с помощью которого данные распределяются по категориям. Прием связан со спецификацией альтернативных категорий или классов, в которые должны помещаться ответы, а самим классам должны назначаться кодовые номера.
I этап код-я заключается в специфицировании категорий или классов, к которым будут относиться ответы. Выбор ответов должен быть взаимоисключающим и исчерпывающим, чтобы каждый ответ логически попадал в одну категорию. Код-е закрытых вопросов и большинства средств балльной оценки не сложно; потому что оно устанавливается при конструировании самой анкеты. Код-е открытых вопросов более сложно и более дорогое, т.к. приходится определять подходящие категории на базе ответов, которые не всегда предсказуемы. Если анкет слишком много, и необходимо использовать для кодирования анкет нескольких кодировщиков, дополнительной проблемой может стать возникновение несоответствия в самом кодировании. Поэтому для получения логической последовательности обработки данных, эту работу необходимо разделять по задачам, а не в равных долях делить анкеты между кодировщиками.
II этап код-я касается назначения кодовых номеров классов. Принято, для обозначения классов использовать цифры, а не буквы. Когда для анализа данных предполагается использовать компьютер, кодирование необходимо выполнять таким образом, чтобы данные оказывались готовыми для ввода в машину, поэтому полезно обеспечить наглядность ввода посредством многоколонной записи. Когда вопрос допускает множество ответов, допускать отдельные колонки для кодирования каждого варианта ответа.
Необходимо использовать ровно столько колонок поля, назначаемого для переменной, сколько необходимо для полного охвата всех ее возможных значений. Кроме того, любому полю должна назначаться не более чем одна переменная.Рекомендуется применять стандартные коды для «отсутствия информации». Так, все ответы «не знаю» должны кодироваться цифрой 8, «нет ответов» - цифрой 9, а «не применялось» обозначаться как 0. Лучше, если во всем исследовании для каждого из этих типов «нет информации» используется один и тот же код.
Завершающий этап код-я состоит в подготовке книги кодов , которая содержит общие инструкции, указывающие, каким образом была закодирована каждая позиция данных. В ней перечисляются коды каждой переменной и категории, включенные в каждый код.
52.Табулирование данных. Табулирование заключается просто в подсчете количества событий, которые попадают в различные категории. Табулирование может принимать форму простой табуляции, или перекрестной табуляции . Простая табуляция - подсчет количества событий, которые попадают в каждую категорию, когда категории базируются на одной переменной.Перекрестная табуляция - подсчет количества событий, которые попадают в каждую из нескольких категорий, когда категории базируются на двух и более переменных, рассматриваемых одновременно.Одномерная табуляция используется в следующих целях:
1. для определения степени безответности позиций анкеты является важной проблемой в большинстве исследований. Когда степень безответности большая, исследование в целом становится сомнительным и возникает необходимость пересмотреть его цели и методы. Возможно использование нескольких стратегий. - Оставить позиции пустыми и описать их количество как отдельную категорию. -Исключать событие с утраченной позицией при анализе с использованием соответствующей переменной. -Подставить значения утраченных позиций анкеты. 2. для локализации грубых ошибок . Грубая ошибка– ошибка, которая возникает при редактировании, кодировании, клавиатурном наборе или табулировании данных.3. для локализации посторонних значений- наблюдение, настолько отличающееся по величине от остальных наблюдений, что возникает необходимость обрабатывать его как особое значение.4. для определения эмпирического распределения рассматриваемой переменной. Лучше всего представить в виде гистограммы.5. для расчета итоговых статистик.
Перекрестная табуляция является важным механизмом для изучения связей внутри и между переменными. В перекрестной табуляции выборка делится на подгруппы. Связь между двумя переменными в пределах категорий размера семьи, называется условной таблицей , позволяющей обнаружить условную связь между переменными.Условные таблицы, построенные на основе одной регулируемой переменной, называются условными таблицами первого порядка . Таблицы, составленные с использованием двух регулируемых переменных, называются условными таблицами второго порядка .В настоящее время табулированные результаты чаще представляются в виде баннеров. Баннер – это последовательныйряд перекрестных табуляций между критерием и несколькими факторными переменными, оформленный в виде единой таблицы.
53.Традиционный, классический метод анализа документов и его составляющая.Традиционный анализ – это цепочка умственных, логических построений, направленных на выявление сути анализируемого материала с определенной, интересующей исследователя точки зрения в каждом конкретном случае. Основным недостатком этого анализа является субъективность. В традиционном анализе различают внешний и внутренний анализ. Внешний анализ – это анализ контекста документа и тех обстоятельств, которые сопутствовали его появлению. Цель внешнего анализа – установить вид документа, его форму, время и место появления, автора и инициатора, какие цели преследовались при его составлении, степень надежности и достоверности, каков его контекст. Внутренний анализ – это исследование содержание документа. Отдельные виды документов из-за своей специфики, требуют специальных методов анализа и привлечения для их выполнения специалистов других областей знаний. Юридический анализ. Он применяется для всех видов юридических документов. Его специфика заключается в том, что разработан особый словарь терминов, в котором значение каждого слова строго однозначно определено.Психологический анализ. Он применяется при оценке отношения автора к какому-либо политическому, экономическому или социальному явлению. На основе таких исследований можно получить представление о формировании общественного мнения, общественных установок и т.д.
54. Формализованный, количественный (контект-анализ) и его состав-е . Его называют часто количественный метод анализа документов (контент-анализ).Суть этих методов сводится к тому, чтобы найти легко подсчитываемые признаки, черты, свойства документа, которые отражали бы определенные существенные стороны содержания. Тогда качественное содержание делается измеримым, становится доступным для точных вычислений.Контент-анализ – это техника выделения заключения проводимого с помощью объективного и систематического выявления соответствующих характеристик текста задачам исследования. Существуют общие принципы, когда применяется контент-анализ:1. Когда требуется высокая степень точности или объективности анализа.2. При наличии большого по объему и несистематизированного материала.3. Когда категории, важные для целей исследования, характеризуются определенной частотой появления в изучаемых документах.Основными направлениями использования контент-анализа являются:
1. Выявление и оценка характеристик текста как индикаторов определенных сторон изучаемого объекта;2. Выявление причин, породивших сообщение; 3. Оценка эффекта воздействия сообщения (например, рекламного).Требование объективности анализа предполагает решение ряда проблем, связанных:1. с выработкой категорий анализа. Категории анализа – это понятие, в соответствии с которыми будут сортироваться единицы. Требования, предъявляемые к категориям:- должны быть исчерпывающими, - взаимоисключаемыми, - надежность.2.С выделение единиц анализа. Единицей анализа (смысловой или качественной) является та часть содержания, которая выделяется как элемент, подводимый под ту или иную категорию. Индикаторами могут быть:- относящиеся к теме слова и словосочетания;- термины;- имена людей;- названия организаций;- географические названия;- пути решения экономических проблем, 3. с выделение единиц счета. Единицы счета обладают разной степенью точности измерения, а так же разным временем, уходящим на кодировку материала, попавшего в выборку. В практике методом контент-анализа были выделены общие единицы счета, отвечающие различным исследовательским требованиям.1.Время – пространство. 2.Появление признаков в тексте
3.Частота появления. При разработке программы маркетинговых исследований необходимо четко определить, какого рода характеристики объекта подвергаются изучению, и в зависимости от этого оценивать документы с точки зрения их адекватности, надежности, достоверности.
Адекватность документа определяется как степень, в которой он отражает интересующие исследователя характеристики объекта.
Надежность оценивается сопоставлением всех данных содержания с какими-то другими данными. Здесь возможны несколько вариантов проверки:
1.Сравнение содержания документов , исходящих из одного источника. Такое сравнение может проводиться:а) во времени б) в различных ситуациях
в) в различных аудиториях .2.Метод независимых источников , т.е. выбираются характеристики из нескольких различных источников информации. Затем различия в характеристиках сравниваются с различиями в содержании сообщений.Оценка достоверности данных документа проводится путем последовательного перебора источников встречающихся в документе ошибок. Источники ошибок можно разделить на две категории:
Случайные (например, опечатки в статистических данных) -систематические.
Систематические ошибки делятся на сознательные и несознательные
Сознательные ошибки часто определяются теми намерениями, которыми руководствуется автор при составлении документа.
ОПРЕДЕЛЕНИЕ ОШИБОК ИЗМЕРЕНИЙ
Ошибки (погрешности), возникающие при измерениях, делятся на два больших класса: погрешности случайные и погрешности систематические. Для уяснения разницы между ними обратимся к конкретному примеру. Допустим, вы определяете массу тела взвешиванием его на рычажных весах. Обычно тело кладется на левую чашку весов, а разновесы – на правую. Плечи весов, разумеется, не могут быть абсолютно одинаковыми. Разница в их длине искажает результаты измерений и, притом, всегда одинаковым образом. Ошибки, сохраняющие величину и знак от опыта к опыту, носят название систематических. К систематическим относятся ошибки, связанные с неравноплечностью весов, неправильным весом гирь, неточной разбивкой шкалы измерительных приборов и т.д.
Однако, систематические ошибки не единственные причины погрешностей измерений. В том же опыте со взвешиванием тела есть ошибки, которые могут изменяться от опыта к опыту. В самом деле, коромысло весов качается с некоторым трением. Поэтому, даже при постоянной нагрузке весов, оно останавливается не всегда в одном и том же месте а в разных местах, лежащих в области, размер которой определяется силами трения. Ошибки в этом случае от опыта к опыту не повторяются.
Случайными ошибками называются ошибки, которые непредсказуемым образом изменяют свою величину и знак от опыта к опыту.
Бывают случаи, когда случайные ошибки не связаны с дефектами аппаратуры, а лежат в сущности изучаемого явления.
Так, например, если вы изучаете радиоактивный распад какого-либо радиоактивного элемента, то число зарегистрированных распадов, скажем, в 1 минуту, не будет оставаться постоянным. В одних измерениях вы зарегистрируете, например, 18,15,12,17 распадов в минуту, в других – 23, 25, 17, 22 распадов. В среднем вы получите 20 распадов в минуту. Отклонение измеренного числа распадов от среднего значения 20 распадов в минуту носит чисто случайный характер. И связано с самой природой изучаемого явления.
Влияние случайных ошибок может быть уменьшено при многократном повторении опыта, т.к. опыты, результаты которых превышают среднее значение будут встречаться столь же часто, как и опыты с результатами меньшими среднего значения.
Уменьшить же вклад систематических ошибок таким способом нельзя. Главной причиной этих погрешностей является несовершенство измерительных приборов. Поэтому для их уменьшения необходимо воспользоваться более совершенными средствами измерений, погрешность которых меньше. Качество измерительных приборов характеризуется их классом точности, т.е. той максимальной погрешностью, которую могут вносить эти приборы в измеряемую величину. Чем выше класс точности прибора тем эта погрешность ниже. Помимо необходимости совершенствовать приборы, можно изменить методику опыта. Например, в опыте со взвешиванием нужно либо уменьшить неравноплечность весов, либо взвешивать тело дважды, один раз на левой чашке весов, другой – на правой и усреднить полученные результаты.
Cтраница 1
Причины систематических ошибок при определении точки эквивалентности рассматриваются в дальнейшем при описании отдельных методов объемного анализа. Для того чтобы уменьшить влияние случайных ошибок на результат, определение повторяют несколько раз.
Причиной систематических ошибок в спектральном анализе при правильной и аккуратной работе почти всегда являются эталоны. Эталон, не дающий систематической ошибки (назовем его идеальным эталоном), должен быть во всех отношениях тождественен с пробой, отличаясь от нее только содержанием анализируемого элемента. Легче всего приблизиться к идеальным эталонам при анализе растворов и газов. Обычно есть различия даже в химическом составе тех и других.
Исследованы причины систематических ошибок дифференциального фотоколориметрического определения фосфора. Установлено, что эти ошибки обусловлены недостаточно точным построением калибровочного графика и малым объемом отбираемой для анализа пробы.
Другими словами, причиной систематической ошибки является неисправность вычислительной машины. Обнаружение систематических ошибок и устранение причин, их порождающих, осуществляется персоналом, обслуживающим машину.
Возможна и такая ситуация, когда причина систематической ошибки известна, но невозможно установить ни ее величину, ни ее знак. Пусть, например, экспериментально сравнивается производительность двух измерительных установок. На каждой из них работает экспериментатор. Можно ли утверждать, что одна установка производительней, по результатам работы этих экспериментаторов, особенно если эти результаты отличаются не очень сильно. Очевидно, нет, так как кроме конструкции установок производительность зависит от экспериментаторов. Сделав по результатам эксперимента вывод, что производительность одной установки на столько-то процентов больше, чем другой, мы допустим ошибку, величину и знак которой невозможно установить. Если в рассмотренном примере экспериментаторы будут поочередно работать то на одной установке, то на другой, ошибка эксперимента будет меньше и сравнительные данные производительности установок - точнее.
Какие из указанных ниже факторов являются причиной систематической ошибки мерной колбы.
В аналитической химии это означает, что нужно выявить причины систематических ошибок (неверных данных) и устранить их, так как сами систематические ошибки нельзя устранить многократным повторением анализа, их можно при этом только выявить.
В то же время использование одного обкатывающегося ролика может стать причиной систематической ошибки.
Если же при проверке бюретки окажется, что в результате неправильного нанесения делений на ней объем 15 мл соответствует в действительности 14 9 мл, то это явится причиной систематической ошибки, которая будет повторяться во время всех работ с данной бюреткой.
Ошибки, совершаемые при измерениях, могут быть систематическими и случайными. Причины систематических ошибок (плохая регулировка приборов) могут быть вскрыты и устранены. Случайные ошибки порождаются большим количеством причин, контролировать которые экспериментатор не может. Учет этих ошибок производится статистическими методами.
Систематическая ошибка - это ошибка, вызываемая причинами, которыми могут быть неточность прибора, неверная его установка, индивидуальные особенности экспериментатора и др. Значение систематической ошибки при повторных опытах остается постоянным или изменяется по определенной закономерности. Поскольку причины систематических ошибок известны, их необходимо исключить. Грубые ошибки возникают вследствие нарушений основных условий измерения, неопытности исследователя. При обработке результатов измерений выявленные промахи в расчет не принимают.
Рассмотрим некоторые причины систематических ошибок в термометрии по сдвигу края поглощения.
Систематические ошибки - это ошибки, вызываемые известными причинами, или причины которых можно установить при детальном рассмотрении процедуры химического анализа. Другими словами, причины систематических ошибок значимы для аналитика. Однако, поскольку систематические ошибки, как правило, не единичны, общий результат анализа может содержать как положительную, так и отрицательную суммарную систематическую ошибку, причем величина ее может быть большой.
Систематические ошибки - это ошибки, вызываемые известными причинами, или причины которых можно установить при детальном рассмотрении процедуры химического анализа. Другими словами, причины систематических ошибок значимы для аналитика.
Выборочное обследование
Создать выборку означает выбрать, кого опрашивать. Часто бывает невозможно и не нужно опрашивать всех членов целевого рынка, чтобы узнать мнение о том или ином вопросе, но важно опросить достаточное число людей нужного типа, чтобы полученные данные были вполне репрезентативными для рынка в целом.
Нахождение правильного состава респондентов имеет важное значение, поскольку исследователь пытается сделать выводы о целевом рынке в целом; во многих случаях при проведении обследования опрашивают мнение не более 100 респондентов, чтобы сделать выводы о потребителях, исчисляющихся миллионами. Это означает, что, когда наступит время анализа, небольшая ошибка в отборе выборки будет умножена многократно.
Рамочная выборка - это список респондентов, из которых исследователь хочет получить выборку. В некоторых случаях бывает, что такой список можно достать: например, если исследователь хочет выборочно обследовать мнение врачей, то он может получить список фамилий и адресов всех врачей страны. После этого будет относительно не сложно составить выборку из этого списка. Более вероятно, однако, что нужного исследователю списка взять негде, например списка людей, игравших в сквош (род упрощенного тенниса) за последние три месяца, которого, скорее всего, не существует. В таких случаях исследователю нужно составить репрезентативную выборку людей с требуемыми характеристиками. Это задание нередко бывает сложным .
В табл. 5.3 представлены некоторые методы создания выборки.
В последнее время наметился переход от использования вероятностных выборок к выборкам пропорциональным, при этом при создании выборок все шире применяются базы данных . Это вызвано тем, что пропорциональную выборку получить легче, полученные с ее помощью данные более надежны, а существование баз данных позволяет легко создавать выборки для почтовых опросов.
Таблица 5.8, Методы создания выборки
|
Метод |
Описание |
Преимущества |
Недостатки |
|
Случайная, или вероятностная, выборка |
Каждый человек, входящий в население в целом, имеет одинаковые шансы быть включенным в выборку |
Дает поперечный срез мнений населения |
Почти невозможно достичь. Большинство так называемых "случайных" выборок имеют серьезные отклонения: например, выбор имен из телефонной книги может казаться случайным, но по сути в такую выборку будут включены только люди, имеющие телефон, и в нее не будут включены даже люди, просто не попавшие в справочник |
|
Пропорциональная выборка |
Сначала проводится анализ населения, часто с использованием данных переписи. Затем устанавливается квота для каждой категории (например, женщины в возрасте 35 лет, 20-летние мужчины, профессионалы среднего возраста), и интервьюерам велят придерживаться квот |
Обеспечивает четкий поперечный срез мнений при условии правильного установления квот |
Часто означает, что интервьюеры отметают респондентов из-за того, что они не подходят под квоты, и к концу дня интервьюеры нередко тратят много времени в поисках этого последнего "35-летнего работника физического труда с двумя детьми" |
|
Стратифицированная выборка |
Аналогична пропорциональной выборке в том смысле, что определяются широкие слои населения, но окончательный выбор респондента производится практически случайно |
Менее расточительное отношение к респондентам, чем в случае пропорциональной выборки, больше гибкости для интервьюеров, а значит, такое обследование обходится дешевле |
Точность ниже, чем в случае пропорциональной выборки |
Техника интервью
При проведении опроса интервьюеру слишком просто "подвести" респондентов к "правильному" высказыванию. Иногда этому способствуют респонденты, сами задавая вопросы; хорошие интервьюеры избегают искушения вмешаться и помочь в этот момент.
Избежать этого можно, сказав, например: "Нам важно узнать именно ваше мнение. Что думаете вы?" или просто посмотрев вопросительно. Можно также порекомендовать заранее объяснить респондентам, что вы не сможете помочь им с ответами.
В случае использования фокус-групп или групповых глубинных интервью возникает проблема, связанная с необходимостью решить, следует ли продолжать ту или иную линию разговора или же оборвать ее. То, что на первый взгляд может показаться абсолютно не относящимся к делу отступлением от темы, может в конечном счете изменить направление дискуссии и позволить сделать какие-либо очень важные выводы; с другой стороны, если интервью превратится в общую болтовню, ничего полезного не получится. В некоторых случаях ведущий может просто спросить, как эта тема относится к предмету исследования. Иногда это позволяет получить быстрое объяснение связи или, в противном случае, быстро вернуться к теме обсуждения.
На практике группы, как правило, придерживаются обсуждаемой темы; отклонения случаются редко и длятся обычно недолго.
Источники систематических ошибок
Систематическая ошибка - это следствие воздействия, в результате которого та или иная внешняя сила делает обследование недостоверным.
Систематическая ошибка выборки
Это происходит, когда выборка является нерепрезентативной для изучаемого населения. Легко попасться в ловушку, думая, что выборка является репрезентативной, когда на самом деле она взята из маленькой популяции. Например, исследователь проводит опрос, допустим, на главной улице, останавливая каждого третьего посетителя магазинов. Это обследование не будет репрезентативным, поскольку оно включает лишь тех, кто пришел в этот день за покупками на главную улицу. Если такого рода обследование предпринято, к примеру, во вторник после полудня, в него может попасть в процентном отношении больше пенсионеров и безработных, чем присутствует во всем населении. Если аналогичное исследование будет проведено в субботу пополудни, то, скорее всего, в него не попадут спортивные болельщики.
Систематическая ошибка интервьюера
Это происходит, когда интервьюер хочет помочь респонденту ответить на вопрос. Интервьюеры, естественно, хотят пройти все вопросы анкеты с минимальными проблемами, к тому же они осознают, что у респондента есть чем заняться кроме того, чтобы отвечать на затруднительные или плохо сформулированные вопросы. Если интервьюер замечает, что респонденты проявляют отрицательную реакцию на некоторые вопросы, он может в будущем пропускать их и "угадывать" ответы. К сожалению, известно, что некоторые недобросовестные интервьюеры подделывают все ответы, если у них возникают трудности с нахождением достаточного количества респондентов для квоты .
Систематическая ошибка интервьюера может быть едва заметной; в не ограниченных временем интервью лицом к лицу "язык тела" интервьюера (выражение лица, жесты и пр.) может передать респонденту сигнал, который приведет к тому, что будет дан некий специфический ответ, или к тому, что часть информации не будет предоставлена.
Систематические и случайные ошибки.
Измеряя любую физическую величину с помощью прибора с конкретной ценой деления w, нам приходилось округлять результат до ближайшего целого деления или хотя бы до значения, соответствующего середине между соседними делениями. Погрешность, которую мы считали равной , можно назвать по сути ошибкой округления . Эта ошибка присутствует всегда и включается в общий класс систематических ошибок. Можно ли ее уменьшить? Конечно, можно взять более дорогой и точный прибор.
Кроме ошибки округления существует предельная ошибка прибора , связанная с неточностью изготовления шкалы на заводе. Неужели кто-то поверил, что интервал на шкале линейки действительно соответствует 1 мм? Конечно нет. Цена деления миллиметровой линейки приблизительно равна 1мм. И эта приблизительность выражается в предельной ошибке, прописанной в заводском паспорте прибора. Допускаемая предельная погрешность, например, для стальной линейки длиной 300 мм составляет мм. И чем длиннее линейка, тем больше приборная погрешность. Для упрощения обработки данных, мы будем учитывать только ошибку округления и пренебрежем приборной.
При измерении интервалов времени с помощью секундомеров вводится систематическая ошибка, которая связана с реакцией человека на нажатие кнопки. Один человек медлителен от природы и нажимает кнопку на секундомере позже начала процесса, второй наоборот – слишком рано. Медицинские исследования этого вопроса дают среднее значение абсолютной погрешности измеряемого интервала с при нажатии кнопки в начале и в конце процесса. Такую ошибку называют субъективной . Вот оно что! Тогда понятен большой разрыв между двумя одновременными измерениями падения кирпича (см. 2.2.1). Его можно объяснить разной реакцией у меня и у моего напарника.
А какие еще ошибки бывают, кроме систематических?
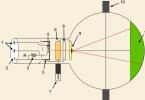
Для ответа на этот вопрос проведем (мысленно) лабораторную работу по измерению дальности полета маленького шарика, выпущенного пружинным пистолетом под углом a к горизонту. Будем стрелять раз, при этом шарик будет оставлять следы на бумаге (для этого нужно всего лишь положить копировальную бумагу поверх простого листа).

Рис.19. Схема эксперимента по измерению дальности полета шарика.
Проведем черту А перпендикулярно оси пистолета (рис.19), соответствующую начальной координате шарика. Параллельно линии А проведем линию В через одну из точек-следов. Измерим расстояние х i между ними и будем называть эту величину дальностью полета. Запишем пример таких измерений:
Таблица 3. Измерения дальности полета шарика с помощью линейки.
| х i , мм |
Почему же результаты отличаются, ведь используется каждый раз один и тот же пистолет и один и тот же шарик? Чтобы не было ветра, я закрыл окно, а разброс данных остался. Может дело в пружине? Заряжая пистолет, каждый раз пружина сжимается немного по-разному? Может шарик каждый раз немного меняет свою траекторию в стволе? А вот это я уже не смогу никак учесть! Сжатие пружины и траектория шарика совершенно случайные величины в этой установке. Таким образом, разброс данных можно объяснить случайностью, и поэтому вводится класс случайных величин, а с ними вместе и особый вид случайных ошибок .
Для обработки набора данных случайной величины вводится среднее значение
![]()
и среднеквадратичное отклонение от среднего
![]() ,
,
Используя данные из табл.3, получим
Если кто-то думает, что списав все цифры с калькулятора, можно получить более точный ответ, я напомню о цене деления линейки и о систематической погрешности округления. Никакого смысла нет тащить за собой цифры в разрядах дальше десятых, потому что ошибка округления мм. И вообще можно ввести жесткое требование к количеству знаков в числах при рассчетах. В промежуточных рассчетах надо оставлять на одну цифру больше, чем количество цифр в исходных данных. Последняя цифра будет запасной и поможет в конце измерений сделать грамотное округление конечного результата. Таким образом, достаточно ограничиться значением
Добавим к табл.3 еще одну строку, где запишем отклонение каждого значения от среднего , т.е.
Таблица 4. Измерения дальности полета шарика с помощью линейки.
| х i , мм | ||||||||
| Δx i =x i – | – 26,6 | 10,4 | – 8,6 | – 0,6 | 31,4 | 2,4 | – 28,6 | 20,4 |
Отклонения от среднего могут быть как положительные, так и отрицательные. Это и понятно: среднее значение всегда лежит где-то посередине набора значений , поэтому оно больше одних значений и меньше других. Для рассчета среднеквадратичного отклонения надо сложить квадраты отклонений и разделить на , не забыв потом взять квадратный корень из результата:
Оказывается, если проделать несколько таких серий по 8 выстрелов, то в каждой серии будет свое среднее значение дальности полета , а среднеквадратичное отклонение этих средних значений будет намного меньше, чем (для простоты будем считать, что среднеквадратичные отклонения в каждой серии равны друг другу) и равно