После того, как определен метод исследования и разработан инструмент, определяются параметры исследования: тип, состав и свойства выборки и её объем. Для определения типа выборки надо воспользоваться таблицами в лекциях: определить объем и свойства генеральной совокупности, затем выбрать модель выборки..
Таблица объемов выборок позволяет определить объем выборок, исходя из заранее заданного показателя надежности P и заранее заданной допустимой величины ошибки е. Р показывает, какую часть генеральной совокупности максимально сможет охватить выборка (это показывает её надежность), а ошибка показывает, какие минимальные расхождения будут допущены между свойствами генеральной совокупности и свойствами выборки.
| Таблица объемов выборок | ||||||||||
| е P | 0,10 | 0,09 | 0,03 | 0,07 | 0,06 | 0,05 | 0,04 | 0,03 | 0,02 | 0,01 |
| 0,75 | ||||||||||
| 0,80 | ||||||||||
| 0,85 | ||||||||||
| 0,90 | ||||||||||
| 0,91 | ||||||||||
| 0,92 | ||||||||||
| 0,93 | ||||||||||
| 0,94 | ||||||||||
| 0,95 | ||||||||||
| 0,96 | ||||||||||
| 0,965 | ||||||||||
| 0,970 | ||||||||||
| 0,975 | ||||||||||
| 0,980 | ||||||||||
| 0,985 | ||||||||||
| 0,990 | ||||||||||
| 0,991 | ||||||||||
| 0,992 | ||||||||||
| 0,993 | ||||||||||
| 0,994 | ||||||||||
| 0,995 | ||||||||||
| 0,996 | ||||||||||
| 0,997 | ||||||||||
| 0,998 | ||||||||||
| 0,999 |
Допустим, мы хотим охватить генеральную совокупность с надежностью не менее 80% и допускаем ошибку нашего исследования не менее 10%. При этом мы ничего не знаем о том, какие значения может принимать исследуемая нами переменная, то есть не имеем никакой априорной информации о генеральной совокупности: ни среднего не знаем, ни возможной дисперсии - ничего. Тогда мы просто ищем соответствующее пересечение в таблице (Р=0,80 , е=0,10): объем выборки составит 41 человек. Таблица составлена из расчета максимального значения дисперсии дихотомической переменной. Видно, что с увеличением точности выборки её объем быстро растет – если в описанном случае мы увидели объем в 41 человек, то для параметров в Р=95% и е=5% (стандартных для большинства исследований) объем составит уже 384 человека. Поэтому таблицей надо пользоваться в случаях, когда генеральная совокупность относительно небольшая и допустимы значительные величины ошибок.
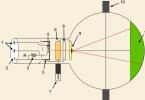
Чтобы обеспечить небольшой объем выборки для относительно большой генеральной совокупности, надо заранее знать параметры распределения изучаемой переменной: среднее значение и дисперсию. При этом можно воспользоваться приведенной ниже номограммой для расчета выборок (номограмма построена для надежности Р=95%, что вполне достаточно). Для использования номограммы надо знать две величины: коэффициент изменчивости v и допустимую величину ошибки е . Коэффициент изменчивости определяется как коэффициент вариации
то есть для его определения надо знать среднее арифметическое и среднее квадратичное отклонение исследуемой переменной.
Для упрощения расчета коэффициента изменчивости надо знать размах вариации, то есть максимальное и минимальное значение, которых может достигать исследуемая переменная. В этом случае расчет v ведется так:
![]() ,где X max
, X min
– максимальное и минимальное значения исследуемой переменной, А
- постоянное действительное положительное число (обычно выбирается между 5 и 6).
,где X max
, X min
– максимальное и минимальное значения исследуемой переменной, А
- постоянное действительное положительное число (обычно выбирается между 5 и 6).
Пример 1 . Предположим, нам известно, что коэффициент изменчивости исследуемой переменной равен 6%. Найдем объем выборки при допустимой ошибке в 5%. Для этого на левой шкале номограммы, обозначенной v% , ищем точку 6. На правой шкале номограммы, обозначенной ε% , ищем выбранное значение ошибки, составляющее 5%. Отмечаем эти точки на линиях и соединяем их по линейке прямой линией. Смотрим, где эта прямая пересекает центральную шкалу, обозначенную n 1 . Это пересечение совершается в точке 6. Следовательно, объем выборки составит 6 человек.
Пример 2 . Пусть нам известно, что коэффициент изменчивости исследуемой переменной равен 16%. Найдем объем выборки для заданной ошибки в 5%. 16% больше 10%, максимально отмеченных на шкале v% , а шкалы логарифмические, поэтому 16 делим на 10 и на шкале v% номограммы ищем точку 1,6. На правой шкале номограммы ε% ищем выбранное значение ошибки, составляющее 5%. Отмечаем эти точки на шкалах и соединяем их по линейке прямой линией. Смотрим, где прямая пересекает центральную шкалу n 1 . Пересечение совершается в точке 0,4. Поскольку мы уменьшили 16% до 1,6%, то есть в 10 раз, то умножаем 0,4 на 100. Объем выборки составит 40 человек (сравните с указанной выше выборкой в 384 человека для Р=95% и е=5% без учета конкретного значения дисперсии).
Пример 3 . Исследуется потребление студентами сигарет, причем изучаются только те, кто курит сигареты (генеральная совокупность - курящие). Допустимая ошибка составляет 5%. Заранее известно (например, данные взяты из источников вторичной маркетинговой информации), что студенты выкуривают сигареты в количестве от одной пачки сигарет в три дня до двух пачек в день, причем в среднем курящему студенту хватает одной пачки сигарет на день. Тогда соответствующие значения будут составлять X max =2, X min =0,33, а среднее составит 1. Коэффициент изменчивости v составит
![]()
и на левой шкале мы откладываем 2,8%, на правой 5%, соединим их и по центральной шкале номограммы получим отметку 1,2 - это значит, что объем выборки должен быть 120 человек.
Пример 4 . Предположим, что при использовании предыдущего примера доступ к целевой репрезентативной группе (курящим) отсутствует. Это значит, что надо включать в выборку как курящих, так и некурящих. В таком случае параметры для расчета будут X max =2, X min =0. Какова будет средняя? Расчет средней по выражению (2+0)/2=1 не является правильным, поскольку прежняя средняя рассчитывалась только для курящих, а сейчас не учтено соотношение размеров групп курящих и некурящих. Например, если доля некурящих составляет 60%, а доля курящих - 40%, то тогда средняя составит 0,4.
Сравним возможные размеры выборок и ошибки исследования:
Если отсутствуют данные о соотношении репрезентативной и нерепрезентативной групп в генеральной совокупности, то расчет коэффициента изменчивости осуществляется через изменение величины А . Как правило, если средняя рассчитывается по выражению (X max +X min )/2, то А уменьшается до 5 и менее.
Как видим, простая случайная выборка для достижения требуемой точности требует значительных объемов. Общий объем выборки можно существенно уменьшить двумя способами:
1) выполняя районирование или стратификацию, то есть выделяя качественно различные группы в генеральной совокупности и размещая выборку именно среди представителей этих групп;
2) выполняя выделение гнезд, то есть разделяя генеральную совокупность на большое количество одинаковых частей и распределяя выборку между этими частями.
При проведении стратифицированной выборки можно поступать следующим образом (см. схему далее).
Первоначально определяется, какой объем априорной информации известен о генеральной совокупности. Для правильно выполненной стратифицированной выборки минимального объема необходимо знать общую численность генеральной совокупности N , число изучаемых страт i , численность каждой страты N i , а внутри каждой страты соответствующее среднее значение изучаемой переменной и её дисперсию. Если все эти параметры известны, то с помощью рассмотренной выше номограммы можно рассчитать объем стратифицированной пропорциональной выборки.
Для этого определяют сначала генеральную дисперсию изучаемой переменной как сумму внутригрупповой и межгрупповой дисперсий, потом определяют генеральное среднее по средним страт, потом определяют коэффициент изменчивости и по номограмме определяют при задании допустимой ошибки общую величину выборки. σ
Генеральная дисперсия равна
где σ 2 р - внутригрупповая дисперсия, а σ 2 m - межгрупповая дисперсия.
Внутригрупповую дисперсию определяют по известным дисперсиям изучаемой переменной внутри каждой страты
где N i - численность i -той страты, σ 2 i - дисперсия i -той страты.
Межгрупповую дисперсию определяют, исходя из известных средних по каждой страте и рассчитанной на их основе генеральной средней:

![]()
Если известно число страт, но неизвестен их объем (и/или объем генеральной совокупности), то рассчитывается сначала общий объем выборки указанным способом, а потом он делится на число страт так, чтобы в каждой страте разместилась бы одинаковая доля выборки - это будет стратифицированная равная выборка.
Если неизвестны дисперсии внутри страт, то необходимо знать размах вариации внутри каждой страты, то есть значения X max и X min . Тогда дисперсии страт можно рассчитать, исходя из выражения

Если неизвестна численность страт, то внутригрупповвая дисперсия рассчитывается как простое среднее арифметическое из дисперсий страт.
Если неизвестны средние в каждой страте, но известен размах вариации, то средние внутри страт определяются как средние между крайними значениями изучаемой переменной
![]()
Если наличие страт неизвестно, но по генеральной совокупности известны параметры среднего, дисперсии и плотности распределения единиц наблюдения, то осуществляется районная выборка по гнездовому или пропорциональному способам. Если единицы наблюдения размещены по территории, где находится генеральная совокупность, относительно равномерно (коэффициент вариации плотности размещения составляет не более 15-25%), то используется выделение гнезд, каждое из которых вмещает в себя одинаковое число единиц наблюдения. Гнезда выделяются так, что имеют одинаковый размер (например, площадь). Число гнезд определяется пропорционально отношению общего размера выборки n к общему числу единиц наблюдения N . Из каждого гнезда отбирается только одна единица наблюдения, размещение выборки по гнездам осуществляется равномерно-механическим или случайным методом.
Если размещение единиц наблюдения по изучаемой территории неравномерно, то она разделяется на районы с одинаковым числом единиц наблюдения в каждом - это порайонная пропорциональная выборка. Для этого рассчитывается общий объем выборки по номограмме, после чего эта выборка распределяется по районам пропорционально численности единиц наблюдения. Внутри районов в этом случае размещение выборки выполняется либо гнездовым, либо иным способом, аналогично известным процедурам размещения выборок.
Пример 5 . Воспользуемся примером 3, изучающим потребление сигарет. Если нет никаких данных о возможных параметрах изучаемой переменной, то при данных Р=95% , е=5% объем выборки составит 384 человека. Выделим две страты - мужчин и женщин. Пусть априори известно (например, из проведения пилотного исследования), что потребление сигарет в пачках за день составляет у мужчин X max =2, X min =0,33, у женщин X max =3, X min =0,1. Вычислим объем выборки в этом случае
![]()
![]()
![]()
![]()
Поскольку о соотношении численностей страт нам ничего не известно, то принимаем, что их численности равны и доли их численностей в генеральной совокупности составляют по 0,5. Тогда внутригрупповая дисперсия будет
а межгрупповая
при генеральном среднем
![]()
Тогда генеральная дисперсия будет
и коэффициент изменчивости составит
![]()
По номограмме при допустимой ошибке 5% объем выборки составит приблизительно 240 человек (более чем на 140 меньше, чем по таблице). В данном случае эта выборка должна быть разделена на 120 мужчин и 120 женщин.
Если и этот объем выборки слишком велик, то нужно увеличивать количество страт, добиваясь того, чтобы размах вариации в каждой страте был минимален, а размеры страт близки, то есть стремиться к минимуму суммарной дисперсии.
В случае, когда известен размер генеральной совокупности в целом, то возможно корректировать размер выборки на бесповторность следующим образом:
1) для известных v% и e рассчитывается по номограмме размер выборки n 1 ;
2) заданная допустимая ошибка корректируется с учетом размера генеральной совокупности

3) по номограмме для скорректированной ошибки e correct и v% находится новый объем выборки n 2 .
Пример 6. Предположим, что исследование проводится для целевого сегмента объемом 1600 единиц наблюдения при v% =25% и e =5%. По номограмме объем выборки тогда составит 100 единиц наблюдения. Корректируем ошибку с учетом размера выборки
![]()
По номограмме скорректированный объем выборки составит (при v% =25% и e =5,2%) 90 единиц наблюдения.
ГЛАВА 1.
В этой части работы студент обрабатывает собранные им данные и делает вывод относительно поставленной задачи: как решить поставленную проблему.
Для обработки студент может использовать MS Excel, SPSS, Statistika for Windows, MatLab, MatCad и другие программы обработки больших массивов данных. Основные задачи, решаемые при использовании этих средств:
верификация данных:
установление законов распределения;
установление взаимосвязей между данными;
классификация и сегментация данных;
прогнозирование развития событий.
Последовательность обработки данных исследования
- расчет в рамках анализа двумерных распределений по каждой таблице данных, коэффициента вариации, корреляционного отношения и стандартных отклонений4
- расчет корреляционной и ковариационной матриц;
- выбор массива данных по заранее заданным условиям;
- вычисление распределений (при учете заданных условий);
- перекодировка (исправление ошибок в данных);
- введение новых показателей (расчет индексов).
Ниже в таблице описаны возможные методы анализа данных. Не следует, разумеется, применять их сразу все. Студент выбирает именно те 1-2 метода, которые наиболее подходят для раскрытия поставленной проблемы.
| Количественные методы анализа данных маркетинговых исследований | |||||||||||||||
| 1.Методы сжатия описательной статистики | 2.Методы анализа систем показателей | ||||||||||||||
| 1.1 Группирование | 1.2 Оценка параметров распределения | 1.3 Ковариационная и корреляционная матрица | |||||||||||||
| 2.1 Ориентация на интегральную качественную характеристику | 2.2 Ориентация на количественный признак | ||||||||||||||
| 2.2.1 Дисперсионный анализ | 2.2.2 Корреляционно-регрессионный анализ | 2.2.3 Причинный анализ | |||||||||||||
| 2.1.1 Без априорной информации об исследуемом признаке | 2.1.2 С априорной информацией о классах признака | 2.1.3 С априорной информацией о возрастании (убывании) признака) | |||||||||||||
| 2.1.1.1 Методы экспертных оценок | 2.1.1.2 Анализ матрицы данных. | ||||||||||||||
| 2.1.3.1 Усиление шкалы по результирующему признаку | 2.1.3.2 Оценка существенности показателя (ранговые корреляции) | ||||||||||||||
| 2.1.1.2.1Факторный анализ | 2.1.1.2.2Латентно-структурный анализ | 2.1.1.2.3Кластерный анализ | 2.1.1.2.4 Методы оценки значимости показателя | ||||||||||||
| 2.1.2.1 Методы усиления номинальной шкалы по результирующему признаку | 2.1.2.2 Оценка существенности показателей системы | ||||||||||||||
| 2.1.2.2.1 Методы теории распознавания образов | 2.1.2.2.2 Методы теории информации | 2.1.2.2.3 Методы теории графов | |||||||||||||
Для определения основных характеристик в зависимости от применявшихся вопросов могут быть применены слудующие методы анализа измерений по шкалам в вопросах:
Статистические методы выявления связей
| Шкала результирующего (итогового) признака | Шкала факторного признака (предиктора) | Метод статистической обработки |
| Количественные (И,О,А,Р) | Количественные (И,О,А,Р) | Регрессии Корреляции |
| Количественные (И,О,А,Р) | Время (И) | Динамика временных рядов |
| Количественные (И,О,А,Р) | Неколичественные (К,П) | Дисперсионный анализ |
| Количественные (И,О,А,Р) | Ковариационный анализ Типологическая регрессия | |
| Неколичественные (К) | Количественные (И,О,А,Р) | Дискриминантный анализ Кластерный анализ Таксономия Расщепление смесей |
| Неколичественные (П) | Неколичественные (К,П) | Ранговые корреляции Анализ таблиц сопряженности |
| Количественные и неколичественные | Количественные и неколичественные | Логические решающие функции |
| Типы шкал в вопросах: И - интервальная, О - относительная, А- абсолютная, Р - разностная, П - порядковая, К - классификационная (номинальная) |
Например, корреляционный анализ для сегментации потребителей выполняется так:
- выделяются средние значения, стандартные отклонения, коэффициент вариации, ошибку среднего значения и доверительный интервал;
- рассчитывается ковариационная и корреляционная матрица (например, в MS Excel);
- вычисляется «близость» объектов в пространстве характеристик (для сегментации);
- вычисляются пути максимальной корреляции в целях группировки переменных;
- вычисляются пути максимального расстояния по матрице расстояний в целях классификации объектов;
- определяются наиболее близкие группы, которые и будут сегментами потребителей;
- проверяется мера близости групп (например, корреляционное отношение).
В конце этой главы студент описывает результаты анализа данных, так чтобы были ясны его решения поставленных задач работы, окончатеьные выводы и их формулировки.
Заключение
В этом разделе студент формулирует полное решение проблемы, поставленной в начале своей работы.
Список литературы
Список использованных источников (список литературы) надлежит выполнять в конце текста работы сообразно ГОСТ 7.1-84, например:
Зиннуров У. Г. Основы маркетинговых исследований: Учебное пособие / У. Г. Зиннуров; Уфимск. гос. авиац. техн. ун-т. Уфа, 1996.- 110 с.
Источники в списке располагаются в алфавитном порядке. На все перечисленные источники в работе необходимо сделать ссылки. Постраничные сноски не допускаются.
В случае, если источником являются сайты Интернета, необходимо указывать полностью адрес того сайта (копируя его адресную строку), на котором была получена конкретная информация. При этом приводится дата последнего обращения к этому сайту, например.
Описание работы калькулятора:
В поле «Объем генеральной совокупности» нужно ввести целое неотрицательное число, равное количеству объектов в совокупности, из которой производится отбор в выборочной совокупности. Например, это может быть количество документов в массиве или, чаще, численность населения, проживающего на определенной территории, или количество людей в целевой группе. На практике часто случаются ситуации, когда выборочная совокупность в 100 и более раз меньше генеральной совокупности. В этом случае генеральная совокупность считается квазибесконечной. Этот параметр установлен по умолчанию (символ «∞» в поле «Объем генеральной совокупности » ).
Далее нужно выбрать (поставить с помощью клика левой кнопки «мыши» точку в нужном кружочке) уровень доверительной вероятности которой будет оценена погрешность выборки или ее объем, то есть поставить с помощью клика левой кнопки «мыши» точку в нужном кружочке. Чем больше заданный уровень доверительной вероятности, тем меньше будет шанс, что реальная погрешность выйдет за пределы теоретической оценки или, что рассчитанный объем выборки будет недостаточным для того, чтобы делать оценки с точностью, не превышающей заданную погрешность. Если доверительную вероятность обозначить P , то вероятность , что оценка погрешности или объема будет неправильной равна 1-Р. При P =0,95 вероятность ошибки равна 0,05 (1 шанс из 20); при P =0,99 эта же вероятность равна 0,01 (1 шанс на 100).
Если Вы хотите рассчитать погрешность выборки определенного объема, то в поле «Объем выборочной совокупности » следует ввести неотрицательное число , равное количеству объектов в выборке . После этого Вы кликнуть левой кнопкой «мыши» кнопку расчет, которая должна стать зеленой после правильного введения Вами исходных данных. В поле «Теоретическая статистическая погрешность » будет выведено число больше 0 и меньше единицы, в котором вместо запятой использована точка «.» (с точностью до 3 знаков после десятичной точки). Если Вы хотите перевести эту погрешность в проценты, просто умножьте число на 100 - перенесите мысленно десятичную запятую на два знака вправо. Так, в приведенном примере по результатам расчета видно, что теоретическая статистическая погрешность случайной вероятностной выборки объемом 1600 единиц с квазибесконечной генеральной совокупности с доверительной вероятностью 0,99 не превышает 0,032 (3,2%).
В том случае, когда необходимо рассчитать объем выборочной совокупности с квазибесконечной генеральной совокупности, достаточной для обеспечения теоретической статистической погрешности не более, чем заданная, Вам нужно заполнить поле «Теоретическая статистическая погрешность» (число от 0 до 1, вместо десятичной запятой «,» – десятичная точка «.» ; проценты нужно перевести в частку от единицы : 3,2%=0,032 т. п.). Также следует задать уровень доверительной вероятности, кликнув левой кнопкой «мыши» точку в нужном кружочке справа от надписи «Доверительная вероятность ». После этого Вам достаточно кликнуть левой клавишей мыши на зеленой кнопке «Расчет» и в поле «Объем выборочной совокупности» Вы увидите результат.
Для ввода новых данных и повторного расчета следует нажать черную кнопку «Очистить » .
Размер выборки требуется определить перед началом большинства количественных исследований. Определение размера выборки не требуется для качественных исследований (обратите внимание, что здесь понимаются формально количественные методы, такие как контент-анализ; простые описательные проекты относятся к количественным). Расчет размера выборки может не выполнять перед проведением предварительных, пилотных исследований (однако такие исследования обычно выполняются перед реальным планированием научного исследования). В случае сомнений, обязательно обратитесь в то учреждение, которое финансирует исследование или включает его в свой план исследований - отсутствие данные о размере выборки одна из наиболее частых причин отказа в утверждении темы
Почему размер выборки важен для исследователя?
При проведении исследований, которые определяют распространенность некоей характеристики в популяции (например, распространенность астмы у детей), расчет размера выборки необходим для того, чтобы полученные оценки имели желаемую степень точности. Например, распространенность заболевания в 10%, полученная на выборке размером в 20 человек будет иметь 95% доверительный интервал от 1% до 31%, что никак нельзя признать ни точно, ни информативной оценкой. С другой стороны, распространенность заболевания в 10%, полученная на выборке размером в 400 человек будет иметь 95% доверительный интервал от 7% до 13%, что может рассматриваться, как достаточно точный результат. оценка размеров выборки позволяет избежать первого из этих двух вариантов.
В исследованиях, направленных на выявление эффекта (например, разность эффективности двух методов лечения, относительный риск заболевания при наличии или отсутствии фактора риска) оценка размера выборки важна для того, чтобы удостовериться в том, что если клинически или биологически важный эффект существует, то он с высокой степенью вероятности будет обнаружен, иными словами анализ даст статистически значимые результаты. Если размер выборки невелик то даже в случае значительных различий между группами будет невозможно доказать, что они являются следствием чего-то иного, кроме как выборочной вариабельности.
Информация необходимая для расчета размера выборки
Методы оценки размера выборки описаны в ряде учебников по статистике, включая Altman, 1991; Bland, 2000; Armitage, Berry и Matthews, 2002. Две книги специализируются на описании методов оценки размеров выборки в разных ситуациях. Для качественных параметров следует проконсультироваться с работой Manchin и соавт. (1998), для качественных - Lemeshow и соавт. (1996). В обеих книгах приведены таблицы, облегчающие расчет размеров выборки. В случае последовательных испытаний, необходимо обратиться к работе Whitehead (1997).Собственно расчеты размера выборки могут быть выполнены с использованием одной из многочисленных компьютерных программ. Так, программа Stata позволяет анализировать размер выборки, необходимый для сравнения средних и пропорций, а также анализа распространенности. Значительно большее количество опций предлагают специализированные пакеты, такие как nQuery Advisor или UnifyPow.
Расчет размера выборки зависит от следующих факторов, которые надо будет сообщить статистику-консультанту:
- Изучаемые в исследовании переменные, включая их типы
- Необходимая мощность исследования
- Необходимый уровень статистической значимости
- Размер эффекта, который имеет клиническую значимость
- Стандартное отклонение для количественных переменных
- Будет ли использоваться одно- или двусторонний тест значимости
- Дизайн исследования, иными словами является ли исследование:
- Рандомизированным контролируемым испытанием
- Кластерным рандомизированным исследованием
- Исследованием эквивалентности
- Нерандомизированным исседованием вмешательства
- Обсервационным исследованием
- Исследованием распространенности
- Изучением чувствительности и специфичности теста
При этом потребуется ответить на ряд дополнительных вопросов:
- Включаются ли в исследование парные данные?
- Будут ли в исследовании измерены повторно одни и те же переменные у одного и того же человека?
- Равны ли включаемые в исследование группы по численности?
- Являются ли данные иерархическими?
Следует принять во внимание, что нерандомизированные исследования различий или взаимосвязей обычно требуют значительно больший размер выборки для того, чтобы принять во внимание при анализе влияние третьих переменных. При этом исследователя интересует абсолютный размер выборки, а не процент, который она составляет от популяции в целом.
Какие статистические термины используются при описании процесса планировании размера выборки
Нулевая и альтернативная гипотезы
Многие типы статистического анализа направлены на сравнение двух видов лечения, процедур или групп пациентов. Численное значение, которое суммирует интересующие исследователя различия называется эффектом. В других исследованиях эффектом может являться коэффициент корреляции, отношение шансов или относительный риск. Затем мы выдвигаем нулевую и альтернативную гипотезы. Обычно нулевая гипотеза гласит, что эффекта нет (различия между группами равны нулю, относительный риск равен единице, корреляционный коэффициент равен нулю), альтернативная гипотеза предполагает, что эффект есть.
Доверительная вероятность (р-оценка)
р-оценка это вероятность наблюдения в исследовании такого же или более сильного эффекта при условии справедливости нулевой гипотезы. Обычно выражается как пропорция (например, р=0.03)
Уровень значимости
Уровень значимости - это пороговое значение для р-оценки, ниже которого нулевая гипотеза должна быть отвергнута и сделано заключение о том, что имеются доказательства эффекта. Обычно уровень значимости устанавливается на значении 5% (Уровень значимости, несмотря на прямую связь с р-оценкой выражается в процентах: 5% уровень значимости эквивалентен р=0.05). Если наблюдаемой значение меньше 5%, то имеется незначительная вероятность, что в исследовании были бы получены такие результаты, если бы истинного эффекта не было. Поэтому принимается гипотеза о наличии эффекта
Уровень значимости 5% также означает, что имеется практически 5% вероятность придти к выводу о наличии эффекта, хотя на самом деле его нет. Иногда более адекватным является использование 1% уровня значимости, особенно если очень важно избежать заключения о том, что эффект существует тогда, когда на самом деле его нет.
Мощность
Мощность - это вероятность того, что нулевая гипотеза будет адекватно отвергнута, иными словами тогда, когда действительно существуют доказательства реальных различий или взаимосвязей. Ее можно рассматривать как "100 процентов минус вероятность пропуска истинного эффекта". поэтому чем выше мощность, тем меньше вероятность пропуска истинного эффекта. Мощность обычно фиксируется на уровне 80%, 90% или 95%. Мощность не должна быть меньше 80%. Если крайне важно, чтобы исследование не пропустило существующего эффекта, надо стремиться достичь мощности 90% или более.
Клинически важный размер эффекта
Это наименьшие различия между средними групп или процентами событий в них (для отношений шансов самый близкий к единице риск), которые еще можно рассматривать как биологически или клинически значимые. Должна быть сформирована выборка такого размера, чтобы если подобные различия существуют, то в исследовании были бы получены статистически значимые результаты.
Односторонний или двухсторонний тест значимости
При двухстороннем тесте нулевая гипотеза заключается в отсутствии различий, а альтернативная гипотеза предполагает, что различия между группами могут идти в любом направлении. При одностороннем тесте альтернативная гипотеза определяет предполагаемое направление различий, например, что терапия лучше, чем плацебо, а нулевая гипотеза включает ситуации, когда эффект препарата и плацебо одинаков и когда препарат приводит к худшему, по сравнению с плацебо, результату.
Если нет серьезных причин для того, чтобы это не делать, следует пользоваться двухсторонней гипотезой. Ожидание того, что различия пойдут в том или ином направлении недостаточное основание для того, чтобы пользоваться односторонним тестом. Исследователи-медики часто оказываются удивлены, если полученный результат идет в разрез с тем, что ожидалось, очень часто подобная находка имеет иные последствия, по сравнению с отсутствием различий и поэтому она должна быть адекватным образом описана. Односторонний тест не позволяет этого сделать. Примеры ситуаций, в которых односторонний тест может оказаться приемлемы приведены в книге Bland и Altman (1994).
Какие переменные должны учитываться при расчете размера выборки
Расчет размера выборки должен базироваться на анализе основной переменной исхода в данном исследовании.
Если в исследование будут включены дополнительные переменные, которые также рассматриваются, как имеющие важное научное значение, то размер выборки должен таковым, чтобы позволить адекватный анализ этих переменных. Для всех важных в научном плане переменных должен быть проведен и представлен расчет размера выборки.
Учет процента отклика и потерь при наблюдении
Расчетный размер выборки указывает количество пациентов в финальной, анализируемой в конце исследования группе. Поэтому количество лиц, которые должны быть вовлечены в исследование должно быть увеличено в соответствии с ожидаемым откликом, потерям при наблюдении, отказом от следования протоколу и другим возможным причинам потери экспериментальных субъектов. Необходимо четко описать взаимосвязь между ожидаемым количеством участников и объемом формируемой выборки.
Соответствие целям исследования и методам статистического анализа
Адекватность размера выборки должна также быть оценена в соответствии с целью исследования. Например, если целью исследования является демонстрация того, что новое лекарство лучше существующего, необходимо добиться того, чтобы размер выборки позволял обнаружить клинически значимые различия между двумя методами лечения. Однако иногда требуется продемонстрировать, что два лекарственных средства клинически эквивалентны. Этот тип исследований часто называют испытанием эквивалентности или "негативным" испытанием. Вопросы определения размера выборки для этих исследований детально описаны в работе Pocock (1983). Размер выборки в исследованиях, направленных на демонстрацию эквивалентности лекарств больше, чем в исследованиях, которые направлены на выявление различий в эффективности. Обязательно следует убедиться в том, что расчеты размеров выборки связаны с целями и задачами исследования и базируются на данных об основной переменной исхода.
Размеры выборки также должны быть адекватны используемым в исследовании методам анализа, поскольку как размер выборки, так и анализ зависят от выбранного дизайна исследования. Обязательно следует удостовериться в том, что предполагаемые методы анализа и расчеты размера выборки совместимы друг с другом.
Примеры расчета размера выборки.
Если планируемое исследование требует оценки одной единственной частоты, сравнения двух средних или сравнения двух частот, расчеты размера выборки (обычно) остаточно просты и поэтому представлены ниже. Однако мы рекомендуем в любом случае проконсультироваться со статистиком по поводу расчетов размера выборки.
Оценка одной единственной частоты
Примечание: приведенная ниже формула базируется на т.н. "методе примерного нормального распределения" и, если только не планируется создавать очень большую выборку, не рекомендуется для оценки частот близких к 0 или 1 (0: или 100%. В подобных случаях следует пользоваться "точными" методами. Подобная ситуация может наблюдаться при изучении чувствительности и специфичности нового метода диагностики, где предполагается наличие частот, близких к 1 (100%). В данном случае следует проконсультироваться со статистиком или, как минимум, воспользоваться специализированными компьютерными программами.
Сценарий: Используя почтовый опросник оценить распространенность нарушений дыхания у пациентов с бронхиальной астмой, находящихся под наблюдением врача общей практики (Thomas и соавт., 2001)
Требующаяся информация:
- Основная переменная исхода = наличие или отсутствие нарушений дыхания
- Предполагаемая частота нарушений = 30% (0.3)
- Требуемая ширина 95% доверительного интервала = 10% (т.е. +/-5% или от 25% до 35%)
Формула для оценки размера выборки одной единственной частоты:
n=15.4*p*(1-p)/W 2
где n - требуемый размер выборки, р - ожидаемая частота результата (в данном случае 0,3) и W - ширина доверительного интервала (в данном случае 0.1)
Подставляя в формулу значения, получаем:
n=15.4*0.3*(1-0.3)/0.1 2 =324
"Для получения доверительного интервала в +/-5% вокруг оценки распространенности в 30% потребуется выборка из 324 человек. Учитывая 70% частоту отклика на предложение участвовать в исследовании, будет распространено 480 опросников"
Сравнение двух частот
Сценарий: Планируется провести рандомизированное плацебо-контролируемое испытание эффективности колонии-стимулирующего фактора для снижения риска сепсиса у недоношенных детей. Ранее проведенное исследование продемонстрировало, что частота развития сепсиса у таких детей составляет 50% в течение 2 недель после рождения и исследователи считают, что снижение этой частоты до 34% будет являться клинически значимым.
Требующаяся информация:
- Основная переменная исхода= наличие или отсутствие сепсиса у новорожденных через 14 дней после рождения (терапия проводится на протяжении максимум 72 часов после рождения). Это качественная переменная, представленная частотами.
- Величина значимых различий = 16% или 0.16 (т.е. 50%-34%)
- Уровень значимости=5%
- Мощность=80%
- Тест=двухсторонний
Формула для расчета размера выборки при сравнении двух частот следующая:
n= 2 *[(p 1 *(1-p 1)+(p 2 *(1-p 2)))]/ 2
где n=размер выборки для каждой группы (общий размер выборки в два раза больше)
р 1 =первая частота - в данном случае 0.50
р 2 =вторая частота - в данном случае 0.34
р 1 -р 2 =клинически значимые различия, в данном случае 0.16
| Таблица значений для А и В |
|
| Уровень значимости |
|
| Мощность |
|
Подставляя значения в формулу получим:
n= 2 *[(0.5*0.5+(0.34*0.66)]/ 2 =146
Таким образом, мы получаем количество наблюдений, необходимое для включения в каждую из групп. Общая численность выборки будет в два раза больше, т.е. 292 ребенка
Описание результатов расчета размера выборки может выглядеть следующим образом:
"Выборка в 292 новорожденных (146 в группе лечения и плацебо) будет достаточным для того, чтобы выявить различия в частоте сепсиса 16% с 80% мощностью на 5% уровне достоверности. 16% различия равны разности между 50% частотой сепсиса к 14 дню наблюдения в группе плацебо и 34% частотой в группе лечения."
Сравнение двух средних
Примечание: описанные ниже расчеты справедливы только для случая, когда две группы имеют один и тот же размер.
Сценарий: планируется рандомизированное контролируемое испытание по сравнению краткосрочного психологического лечения в сравнении с обычным лечением для борьбы с суицидальными тенденциями у пациентов, госпитализированных после суицидальной попытки отравления. Суицидальные тенденции измеряются с помощью шкалы Бека. Стандартное отклонение для оценок по этой шкале составляет 7.7 (данные предшествующих исследований) и клинически значимыми считаются различия в 5 баллов по шкале Бека. Предполагается, что из группы лечения выйдут до трети пациентов (Guthrie и соавт., 2001)
Необходимая информация:
- Основная переменная исхода= шкала суицидальных тенденций Бека. Непрерывная переменная описываемая средними значениями
- Стандартное отклонение=7.7 баллов
- Размер клинически значимого эффекта= 5 баллов
- Уровень значимости=5%
- Мощность=80%
- Тест=двухсторонний
Формула для расчета размера выборки при сравнении двух средних следующая:
n= 2 *2*SD 2 /DIFF 2
где n=размер выборки для каждой группы (общий размер выборки в два раза бльше)
SD= стандартное отклонения для основной переменной исхода, в данном случае 7.7
DIFF=клинически важный эффект, в данном случае 5.0
А - зависит от уровня значимости (см. таблицу) - в данном случае 1.96
В - зависит от мощности (см. таблицу) - в данном случае 0.84
| Таблица значений для А и В |
|
| Уровень значимости |
|
| Мощность |
|
Подставляя необходимые значения в формулу получаем:
n= 2 *2*7.7 2 /5.0 2 =38
Таким образом, мы получаем количество наблюдений, необходимое для включения в каждую из групп. Общая численность выборки будет в два раза больше, т.е. 76 человек.
Адекватное описание оценки размеров выборки будет выглядеть следующим образом:
"Для выявления различий в 5 баллов по шкале суицидальных тенденций Бека на 5% уровне значимости с 80% мощностью, принимая стандартное отклонение равным 7.7 баллам, потребуется 38 человек в группу вмешательства и контроля. Это число было увеличено до 60 в группе (общее количество наблюдений 120), для того, чтобы компенсировать потери при наблюдении, составляющие обычно около трети обследуемых"
Примеры неадекватных описаний оценок размера необходимой выборки
Пример 1
"Предшествующее исследование в данной области использовало выборку в 150 человек и получило высоко достоверные результаты (р=0.014), поэтому в данное исследование включается аналогичное количество пациентов"
Предшествующие исследования могли оказаться просто "везучими" в том смысле, что найденные ими значимые результаты являются следствием случайного варьирования выборочных средних. Необходимо рассчитывать размер выборки для данного исследования - включая такие детали, как мощность исследования, уровень значимости, основная изучаемая переменная, размер клинически значимого эффекта, стандартное отклонение (для количественных переменных) и размер каждой группы, если в исследовании будет несколько групп
Пример 2.
"Расчет размера выборки не проводился, поскольку предварительная информация для ее оценки отсутствовала"
Необходимо тщательно проанализировать литературу, чтобы найти информацию, необходимую для расчета размера выборки. Если такой информации нет, можно организовать небольшое предварительное исследование для сбора этой информации.
Если отсутствуют данные о значении стандартного отклонения, расчеты размера выборки могут быть даны в более общем виде, например различия, являющиеся клинически эффективными могут быть описаны не в абсолютных значениях, а в единицах стандартного отклонения.
Вместе с тем, если пишется заявка на грант, направленный на финансирование пилотного исследования для сбора информации, необходимой для расчета размера выборки последующего крупного исследования, то в такой заявке расчет размера выборки не проводится.
"В клинику в течение года поступает 50 пациентов с данным заболеванием. Около 10% из них могут отказаться от участия в исследовании. Поэтому в течение двух лет можно будет набрать выборку размером в 90 человек"
Хотя большинство исследований должны уравновешивать возможности их организации с мощностью, размер выборки не должен определяться на основании только количества доступных для исследования пациентов.
В ситуациях, когда количество пациентов является ограничивающим размер выборки фактором, расчеты все равно должны проводиться для того, чтобы установить а) мощность исследования с данным количеством пациентов по отношению к клинически важным различиям или б) размер эффекта, который может быть выявлен в исследовании данного размера (учитывая его мощность).
В тех случаях, когда доступное количество пациентов слишком мало для того, чтобы выявить клинически значимые различия, можно подумать об увеличении продолжительности исследования или проведения совместного с несколькими исследователями многоцентрового испытания.
Литература
- Altman DG. (1991) Practical Statistics for Medical Research. Chapman and Hall, London.
- Armitage P, Berry G, Matthews JNS. (2002) Statistical Methods in Medical Research, 4th ed. Blackwell, Oxford.
- Bland JM and Altman DG. (1994). One and two sided tests of significance. British Medical Journal 309 248.
- Bland M. (2000) An Introduction to Medical Statistics, 3rd. ed. Oxford University Press, Oxford.
- Elashoff JD. (2000) nQuery Advisor Version 4.0 User"s Guide. Los Angeles, CA.
- Guthrie E, Kapur N, Mackway-Jones K, Chew-Graham C, Moorey J, Mendel E, Marino-Francis F, Sanderson S, Turpin C, Boddy G, Tomenson B. (2001) Randomised controlled trial of brief psychological intervention after deliberate self poisoning. British Medical Journal 323, 135-138.
- Lemeshow S, Hosmer DW, Klar J & Lwanga SK. (1996) Adequacy of sample size in health studies. John Wiley & Sons, Chichester.
- Machin D, Campbell MJ, Fayers P, Pinol, A. (1998) Statistical Tables for the Design of Clinical Studies, Second Edition Blackwell, Oxford.
- Pocock SJ. (1983) Clinical Trials: A Practical Approach. John Wiley and Sons, Chichester.
- Thomas M, McKinley RK, Freeman E, Foy C. (2001) Prevalence of dysfunctional breathing in patients treated for asthma in primary care: cross sectional survey. British Medical Journal 322, 1098-1100.
- Whitehead, J. (1997) The Design and Analysis of Sequential Clinical Trials, revised 2nd. ed. Chichester, Wiley.
Статистическая совокупность - множество единиц, обладающих массовостью, типичностью, качественной однородностью и наличием вариации.
Статистическая совокупность состоит из материально существующих объектов (Работники, предприятия, страны, регионы), является объектом .
Единица совокупности — каждая конкретная единица статистической совокупности.
Одна и таже статистическая совокупность может быть однородна по одному признаку и неоднородна по другому.
Качественная однородность — сходство всех единиц совокупности по какому-либо признаку и несходство по всем остальным.
В статистической совокупности отличия одной единицы совокупности от другой чаще имеют количественную природу. Количественные изменения значений признака разных единиц совокупности называются вариацией.
Вариация признака — количественное изменение признака (для количественного признака) при переходе от одной единицы совокупности к другой.
Признак - это свойство, характерная черта или иная особенность единиц, объектов и явлений, которая может быть наблюдаема или измерена. Признаки делятся на количественные и качественные. Многообразие и изменчивость величины признака у отдельных единиц совокупности называется вариацией .
Атрибутивные (качественные) признаки не поддаются числовому выражению (состав населения по полу). Количественные признаки имеют числовое выражение (состав населения по возрасту).
Показатель — это обобщающая количественно качестванная характеристика какого-либо свойства единиц или совокупности в цельм в конкретных условиях времени и места.
Система показателей — это совокупность показателей всесторонне отражающих изучаемое явление.
Например, изучается зарплата:- Признак — оплата труда
- Статистическая совокупность — все работники
- Единица совокупности — каждый работник
- Качественная однородность — начисленная зарплата
- Вариация признака — ряд цифр
Генеральная совокупность и выборка из нее
Основу составляет множество данных, полученных в результате измерения одного или нескольких признаков. Реально наблюдаемая совокупность объектов, статистически представленная рядом наблюдений случайной величины , является выборкой , а гипотетически существующая (домысливаемая) — генеральной совокупностью . Генеральная совокупность может быть конечной (число наблюдений N = const ) или бесконечной (N = ∞ ), а выборка из генеральной совокупности — это всегда результат ограниченного ряда наблюдений. Число наблюдений , образующих выборку, называется объемом выборки . Если объем выборки достаточно велик (n → ∞ ) выборка считается большой , в противном случае она называется выборкой ограниченного объема . Выборка считается малой , если при измерении одномерной случайной величины объем выборки не превышает 30 (n <= 30 ), а при измерении одновременно нескольких (k ) признаков в многомерном пространстве отношение n к k не превышает 10 (n/k < 10) . Выборка образует вариационный ряд , если ее члены являются порядковыми статистиками , т. е. выборочные значения случайной величины Х упорядочены по возрастанию (ранжированы), значения же признака называются вариантами .
Пример . Практически одна и та же случайно отобранная совокупность объектов — коммерческих банков одного административного округа Москвы, может рассматриваться как выборка из генеральной совокупности всех коммерческих банков этого округа, и как выборка из генеральной совокупности всех коммерческих банков Москвы, а также как выборка из коммерческих банков страны и т.д.
Основные способы организации выборки
Достоверность статистических выводов и содержательная интерпретация результатов зависит от репрезентативности выборки, т.е. полноты и адекватности представления свойств генеральной совокупности, по отношению к которой эту выборку можно считать представительной. Изучение статистических свойств совокупности можно организовать двумя способами: с помощью сплошного и несплошного . Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности , а несплошное (выборочное) наблюдение — только его части.
Существуют пять основных способов организации выборочного наблюдения:
1. простой случайный отбор , при котором объектов случайно извлекаются из генеральной совокупности объектов (например с помощью таблицы или датчика случайных чисел), причем каждая из возможных выборок имеют равную вероятность. Такие выборки называются собственно-случайными ;
2. простой отбор с помощью регулярной процедуры осуществляется с помощью механической составляющей (например, даты, дня недели, номера квартиры, буквы алфавита и др.) и полученные таким способом выборки называются механическими ;
3. стратифицированный отбор заключается в том, что генеральная совокупность объема подразделяется на подсовокупности или слои (страты) объема так что . Страты представляют собой однородные объекты с точки зрения статистических характеристик (например, население делится на страты по возрастным группам или социальной принадлежности; предприятия — по отраслям). В этом случае выборки называются стратифицированными (иначе, расслоенными, типическими, районированными );
4. методы серийного отбора используются для формирования серийных или гнездовых выборок . Они удобны в том случае, если необходимо обследовать сразу "блок" или серию объектов (например, партию товара, продукцию определенной серии или население при территориально-административном делении страны). Отбор серий можно осуществить собственно-случайным или механическим способом. При этом проводится сплошное обследование определенной партии товара, или целой территориальной единицы (жилого дома или квартала);
5. комбинированный (ступенчатый) отбор может сочетать в себе сразу несколько способов отбора (например, стратифицированный и случайный или случайный и механический); такая выборка называется комбинированной .
Виды отбора
По виду различаются индивидуальный, групповой и комбинированный отбор. При индивидуальном отборе в выборочную совокупность отбираются отдельные единицы генеральной совокупности, при групповом отборе — качественно однородные группы (серии) единиц, а комбинированный отбор предполагает сочетание первого и второго видов.
По методу отбора различают повторную и бесповторную выборку.
Бесповторным называется отбор, при котором попавшая в выборку единица не возвращается в исходную совокупность и в дальнейшем выборе не участвует; при этом численность единиц генеральной совокупности N сокращается в процессе отбора. При повторном отборе попавшая в выборку единица после регистрации возвращается в генеральную совокупность и таким образом сохраняет равную возможность наряду с другими единицами быть использованной в дальнейшей процедуре отбора; при этом численность единиц генеральной совокупности N остается неизменной (метод в социально-экономических исследованиях применяется редко). Однако, при большом N (N → ∞) формулы для бесповторного отбора приближаются к аналогичным для повторного отбора и практически чаще используются последние (N = const ).
Основные характеристики параметров генеральной и выборочной совокупности
В основе статистических выводов проведенного исследования лежит распределение случайной величины , наблюдаемые же значения (х 1 , х 2 , … , х n) называются реализациями случайной величины Х (n — объем выборки). Распределение случайной величины в генеральной совокупности носит теоретический, идеальный характер, а ее выборочный аналог является эмпирическим распределением. Некоторые теоретические распределения заданы аналитически, т.е. их параметры определяют значение функции распределения в каждой точке пространства возможных значений случайной величины . Для выборки же функцию распределения определить трудно, а иногда невозможно, поэтому параметры оценивают по эмпирическим данным, а затем их подставляют в аналитическое выражение, описывающее теоретическое распределение. При этом предположение (или гипотеза ) о виде распределения может быть как статистически верным, так и ошибочным. Но в любом случае восстановленное по выборке эмпирическое распределение лишь грубо характеризует истинное. Важнейшими параметрами распределений являются математическое ожидание и дисперсия .
По своей природе распределения бывают непрерывными и дискретными . Наиболее известным непрерывным распределением является нормальное . Выборочными аналогами параметров идля него являются: среднее значение и эмпирическая дисперсия . Среди дискретных в социально-экономических исследованиях наиболее часто применяется альтернативное (дихотомическое) распределение. Параметр математического ожидания этого распределения выражает относительную величину (или долю ) единиц совокупности, которые обладают изучаемым признаком (она обозначена буквой ); доля совокупности, не обладающая этим признаком, обозначается буквой q (q = 1 — p) . Дисперсия же альтернативного распределения также имеет эмпирический аналог .
В зависимости от вида распределения и от способа отбора единиц совокупности по-разному вычисляются характеристики параметров распределения. Основные из них для теоретического и эмпирического распределений приведены в табл. 9.1.
Долей выборки k n называется отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
k n = n/N .
Выборочная доля w — это отношение единиц, обладающих изучаемым признаком x к объему выборки n :
w = n n /n .
Пример. В партии товара, содержащей 1000 ед., при 5% выборке доля выборки k n в абсолютной величине составляет 50 ед. (n = N*0,05); если же в этой выборке обнаружено 2 бракованных изделия, то выборочная доля брака w составит 0,04 (w = 2/50 = 0,04 или 4%).
Так как выборочная совокупность отлична от генеральной, то возникают ошибки выборки .
Таблица 9.1 Основные параметры генеральной и выборочной совокупностей
Ошибки выборки
При любом (сплошном и выборочном) могут встретиться ошибки двух видов: регистрации и репрезентативности. Ошибки регистрации могут иметь случайный и систематический характер. Случайные ошибки складываются из множества различных неконтролируемых причин, носят непреднамеренный характер и обычно по совокупности уравновешивают друг друга (например, изменения показателей прибора при температурных колебаниях в помещении).
Систематические ошибки тенденциозны, так как нарушают правила отбора объектов в выборку (например, отклонения в измерениях при изменении настройки измерительного прибора).
Пример. Для оценки социального положения населения в городе предусмотрено обследовать 25% семей. Если при этом выбор каждой четвертой квартиры основан на ее номере, то существует опасность отобрать все квартиры только одного типа (например, однокомнатные), что обеспечит систематическую ошибку и исказит результаты; выбор же номера квартиры по жребию более предпочтителен, так как ошибка будет случайной.
Ошибки репрезентативности присущи только выборочному наблюдению, их невозможно избежать и они возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Значения показателей, получаемых по выборке, отличаются от показателей этих же величин в генеральной совокупности (или получаемых при сплошном наблюдении).
Ошибка выборочного наблюдения есть разность между значением параметра в генеральной совокупности и ее выборочным значением. Для среднего значения количественного признака она равна: , а для доли (альтернативного признака) — .
Ошибки выборки свойственны только выборочным наблюдениям. Чем больше эти ошибки, тем больше эмпирическое распределение отличается от теоретического. Параметры эмпирического распределения и являются случайными величинами, следовательно, ошибки выборки также являются случайными величинами, могут принимать для разных выборок разные значения и поэтому принято вычислять среднюю ошибку .
Средняя ошибка выборки есть величина , выражающая среднее квадратическое отклонение выборочной средней от математического ожидания. Эта величина при соблюдении принципа случайного отбора зависит прежде всего от объема выборки и от степени варьирования признака: чем больше и чем меньше вариация признака (следовательно, и значение ), тем меньше величина средней ошибки выборки . Соотношение между дисперсиями генеральной и выборочной совокупностей выражается формулой:
т.е. при достаточно больших можно считать, что . Средняя ошибка выборки показывает возможные отклонения параметра выборочной совокупности от параметра генеральной. В табл. 9.2 приведены выражения для вычисления средней ошибки выборки при разных методах организации наблюдения.
Таблица 9.2 Средняя ошибка (m) выборочных средней и доли для разных видов выборки
Где - средняя из внутригрупповых выборочных дисперсий для непрерывного признака;
Средняя из внутригрупповых дисперсий доли;
— число отобранных серий, — общее число серий;
 ,
,
где — средняя -й серии;
— общая средняя по всей выборочной совокупности для непрерывного признака;
 ,
,
где — доля признака в -й серии;
— общая доля признака по всей выборочной совокупности.
Однако о величине средней ошибки можно судить лишь с определенной, вероятностью Р (Р ≤ 1). Ляпунов А.М. доказал, что распределение выборочных средних , a следовательно, и их отклонений от генеральной средней, при достаточно большом числе приближенно подчиняется нормальному закону распределения при условии, что генеральная совокупность обладает конечной средней и ограниченной дисперсией.
Математически это утверждение для средней выражается в виде:

а для доли выражение (1) примет вид:
где  -
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.
-
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.

Следовательно, выражение (3) может быть прочитано так: с вероятностью Р = 0,683 (68,3%) можно утверждать, что разность между выборочной и генеральной средней не превысит одной величины средней ошибки m (t = 1) , с вероятностью Р = 0,954 (95,4%) — что она не превысит величины двух средних ошибок m (t = 2) , с вероятностью Р = 0,997 (99,7%) — не превысит трех значений m (t = 3) . Таким образом, вероятность того, что эта разность превысит трехкратную величину средней ошибки определяет уровень ошибки и составляет не более 0,3% .
В табл. 9.3 приведены формулы для вычисления предельной ошибки выборки.
Таблица 9.3 Предельная ошибка (D) выборки для средней и доли (р) для разных видов выборочного наблюдения
Распространение выборочных результатов на генеральную совокупность
Конечной целью выборочного наблюдения является характеристика генеральной совокупности. При малых объемах выборки эмпирические оценки параметров ( и ) могут существенно отклоняться от их истинных значений ( и ). Поэтому возникает необходимость установить границы, в пределах которых для выборочных значений параметров ( и ) лежат истинные значения ( и ).
Доверительным интервалом какого-либо параметра θгенеральной совокупности называется случайная область значений этого параметра, которая с вероятностью близкой к 1 (надежностью ) содержит истинное значение этого параметра.
Предельная ошибка выборки Δ позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы , которые равны:
Нижняя граница доверительного интервала получена путем вычитания предельной ошибки из выборочного среднего (доли), а верхняя — путем ее добавления.
Доверительный интервал для средней использует предельную ошибку выборки и для заданного уровня достоверности определяется по формуле:
Это означает, что с заданной вероятностью Р
, которая называется доверительным уровнем и однозначно определяется значением t
, можно утверждать, что истинное значение средней лежит в пределах от ![]() ,а истинное значение доли — в пределах от
,а истинное значение доли — в пределах от
При расчете доверительного интервала для трех стандартных доверительных уровней Р = 95%, Р = 99% и Р = 99,9% значение выбирается по . Приложения в зависимости от числа степеней свободы . Если объем выборки достаточно велик, то соответствующие этим вероятностям значения t равны: 1,96, 2,58 и 3,29 . Таким образом, предельная ошибка выборки позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы:
Распространение результатов выборочного наблюдения на генеральную совокупность в социально-экономических исследованиях имеет свои особенности, так как требует полноты представительности всех ее типов и групп. Основой для возможности такого распространения является расчет относительной ошибки :

где Δ % - относительная предельная ошибка выборки; , .
Существуют два основных метода распространения выборочного наблюдения на генеральную совокупность: прямой пересчет и способ коэффициентов .
Сущность прямого пересчета заключается в умножении выборочного среднего значения!!\overline{x} на объем генеральной совокупности .
Пример . Пусть среднее число детей ясельного возраста в городе оценено выборочным методом и составило человека. Если в городе 1000 молодых семей, то число необходимых мест в муниципальных детских яслях получают умножением этой средней на численность генеральной совокупности N = 1000, т.е. составит 1200 мест.
Способ коэффициентов целесообразно использовать в случае, когда выборочное наблюдение проводится с целью уточнения данных сплошного наблюдения.
При этом используют формулу:
где все переменные — это численность совокупности:
Необходимый объем выборки
Таблица 9.4 Необходимый объем (n) выборки для разных видов организации выборочного наблюдения
При планировании выборочного наблюдения с заранее заданным значением допустимой ошибки выборки необходимо правильно оценить требуемый объем выборки . Этот объем может быть определен на основе допустимой ошибки при выборочном наблюдении исходя из заданной вероятности , гарантирующей допустимую величину уровня ошибки (с учетом способа организации наблюдения). Формулы для определения необходимой численности выборки n легко получить непосредственно из формул предельной ошибки выборки. Так, из выражения для предельной ошибки:
непосредственно определяется объем выборки n :
Эта формула показывает, что с уменьшением предельной ошибки выборки Δ существенно увеличивается требуемый объем выборки , который пропорционален дисперсии и квадрату критерия Стьюдента .
Для конкретного способа организации наблюдения требуемый объем выборки вычисляется согласно формулам, приведенным в табл. 9.4.
Практические примеры расчета
Пример 1. Вычисление среднего значения и доверительного интервала для непрерывного количественного признака.
Для оценки скорости расчета с кредиторами в банке проведена случайная выборка 10 платежных документов. Их значения оказались равными (в днях): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Необходимо с вероятностью Р = 0,954 определить предельную ошибку Δ выборочной средней и доверительные пределы среднего времени расчетов.
Решение. Среднее значение вычисляется по формуле из табл. 9.1 для выборочной совокупности
![]()
Дисперсия вычисляется по формуле из табл. 9.1.
![]()
Средняя квадратическая погрешность дня.
Ошибка средней вычисляется по формуле:
![]()
т.е. среднее значение равно x ± m = 12,0 ± 2,3 дней .
Достоверность среднего составила
![]()
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, и для Р = 0,954 уровня достоверности.
Таким образом, среднее значение равно `x ± D = `x ± 2m = 12,0 ± 4,6, т.е. его истинное значение лежит в пределах от 7,4 до16,6 дней.
Использование таблицы Стьюдента. Приложения позволяет заключить, что для n = 10 — 1 = 9 степеней свободы полученное значение достоверно с уровнем значимости a £ 0,001, т.е. полученное значение среднего достоверно отличается от 0.
Пример 2. Оценка вероятности (генеральной доли) р.
При механическом выборочном способе обследования социального положения 1000 семей выявлено, что доля малообеспеченных семей составила w = 0,3 (30%) (выборка была 2% , т.е. n/N = 0,02 ). Необходимо с уровнем достоверности р = 0,997 определить показатель р малообеспеченных семей во всем регионе.
Решение. По представленным значениям функции Ф(t) найдем для заданного уровня достоверности Р = 0,997 значение t = 3 (см. формулу 3). Предельную ошибку доли w определим по формуле из табл. 9.3 для бесповторного отбора (механическая выборка всегда является бесповторной):
Предельная относительная ошибка выборки в % составит:
Вероятность (генеральная доля) малообеспеченных семей в регионе составит р=w±Δ w , а доверительные пределы р вычисляются исходя из двойного неравенства:
w — Δ w ≤ p ≤ w — Δ w , т.е. истинное значение р лежит в пределах:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Таким образом, с вероятностью 0,997 можно утверждать, что доля малообеспеченных семей среди всех семей региона составляет от 28,6% до 31,4%.
Пример 3. Вычисление среднего значения и доверительного интервала для дискретного признака, заданного интервальным рядом.
В табл. 9.5. задано распределение заявок на изготовление заказов по срокам их выполнения предприятием.
Таблица 9.5 Распределение наблюдений по срокам появленияРешение. Средний срок выполнения заявок вычисляется по формуле:
Средний срок составит:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 мес.
Тот же ответ получим, если используем данные о р i из предпоследней колонки табл. 9.5, используя формулу:
Заметим, что середина интервала для последней градации находится путем искусственного ее дополнения шириной интервала предыдущей градации равной 60 — 36 = 24 мес.
Дисперсия вычисляется по формуле
![]()
где х i - середина интервального ряда.
Следовательно!!\sigma = \frac {20^2 + 14^2 + 1 + 25^2 + 49^2}{4}, а средняя квадратическая погрешность .
Ошибка средней вычисляется по формуле мес., т.е. среднее значение равно!!\overline{x} ± m = 23,1 ± 13,4.
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, для 0,954 уровня достоверности:
Таким образом, среднее значение равно:
т.е. его истинное значение лежит в пределах от 0 до 50 мес.
Пример 4. Для определения скорости расчетов с кредиторами N = 500 предприятий корпорации в коммерческом банке необходимо провести выборочное исследование методом случайного бесповторного отбора. Определить необходимый объем выборки n, чтобы с вероятностью Р = 0,954 ошибка среднего значения выборки не превышала 3-х дней, если пробные оценки показали, что среднее квадратическое отклонение s составило 10 дней.
Решение . Для определения числа необходимых исследований n воспользуемся формулой для бесповторного отбора из табл. 9.4:

В ней значение t определяется из для уровня достоверности Р = 0,954. Оно равно 2. Среднее квадратическое значение s = 10, объем генеральной совокупности N = 500, а предельная ошибка среднего значения Δ x = 3. Подставляя эти значения в формулу, получим:
![]()
т.е. выборку достаточно составить из 41 предприятия, чтобы оценить требуемый параметр — скорость расчетов с кредиторами.
В каждой профессии есть свой набор любимых вопросов. Для исследователей рынка этот список возглавляет, безусловно, вопрос о размере выборки. Обычно его формулируют так:
- Мы хотели бы заказать исследование по посетителям московских торговых центров. Какая нам нужна выборка?
- Наша целевая аудитория – примерно 300 000 человек. Сколько людей нам нужно опросить, чтобы было репрезентативно? А если целевая аудитория будет 3 млн?
- Нам нужно оценить потенциал продаж квартир в Санкт-Петербурге жителям северных городов России. Какую сделать выборку?
Главное заблуждение о размере выборки
Многие уверены, что чем больше размер целевой группы, тем больше должен быть размер выборки. Поэтому, якобы, чтобы узнать мнение жителей маленького города, достаточно опросить человек 200-300, ну а для выяснения мнения по России в целом и 5000 будет мало.
Между тем, этот стереотип не имеет ничего общего с реальностью. Размер выборки не зависит от численности целевой группы (на языке статистики она называется «генеральной совокупностью») и определяется двумя совершенно другими факторами. Единственное исключение из этого правила – случаи, когда генеральная совокупность очень маленькая, например, 1-2 тысячи человек, но такие ситуации в реальной практике маркетинговых исследований встречаются редко.
Два фактора, от которых зависит размер выборки
Размер выборки массового опроса зависит от двух факторов:
- Точности данных, которые нужно получить на выходе – это та самая «статистическая погрешность». Для выборки в 100 респондентов она будет в пределах плюс-минус 10%, а для выборки в 1000 респондентов – в пределах плюс-минус 3,1%. Более подробно об этом – ниже.
- Количества и размера подгрупп, на которые нужно разбивать выборку при анализе. Например, если проводится электоральное исследование, то в основном нас будет интересовать ядро активных избирателей. Как правило, доля «ядра» редко превышает 20-25% от всего населения. Поэтому размер выборки нужно рассчитывать так, чтобы одна четверть от ее общего объема позволяла проводить полноценный статистический анализ.
Две разновидности ошибки выборки
Любое выборочное наблюдение (то есть когда мы опрашиваем не всех подряд, а делаем случайный отбор из генеральной совокупности) сопряжено с погрешностью данных. Эту погрешность обычно называют «ошибкой выборки». Она может быть двух видов:
- Систематическая – связана с ошибками проектирования выборки. Оценить ее размер, направление и степень смещения очень сложно, чаще всего – невозможно. Например, если вопросы респондентам будут задавать представители маргинальных социальных слоев, это повлияет на готовность участвовать в исследовании со стороны представителей более обеспеченных групп населения. В итоге это приведет к крайне трудно оцениваемой систематической ошибке и искажению данных.
- Случайная – связана с действием законов статистики. Ее размер легко рассчитывается по формулам математической статистики и теории вероятности. Они позволяют делать обоснованные выводы о доверительном интервале признака. Например, если статистическая погрешность составляет плюс-минус 10%, а полученное значение показателя оказалось равно 25%, то доверительный интервал равен от 15% до 35%.

Задача исследователя – собрать данные так, чтобы минимизировать систематическую ошибку выборки. Тогда можно будет свести статпогрешность лишь к случайной ошибке, которую можно рассчитать по формулам.
Как рассчитать размер случайной ошибки выборки
Случайная ошибка выборки зависит не только от объема выборки, но и от дисперсии, то есть степени однородности данных. Чем однороднее данные (т.е. чем меньше разброс полученных значений, или дисперсия), тем меньше ошибка выборки.
Существует формула расчета случайной ошибки выборки, однако для удобства рекомендуем пользоваться онлайн-калькуляторами, например, вот этим . Он позволяет легко провести два вида расчета:
- рассчитать величину статистической погрешности на основе размера выборки и предполагаемой дисперсии;
- определить размер выборки, требуемый для получения оценки нужной степени точности.

В качестве параметра доверительной надежности (одно из полей в калькуляторе) обычно используется значение в 95%. Это означает, что в 95% случаев распределение признака в генеральной совокупности попадет в рассчитанный доверительный интервал (т.е. само значение признака в выборке плюс-минус размер статистической погрешности). Реже используется значение надежности в 97% или 99% – оно, соответственно, означает, что подобное попадание произойдет в 97% или 99% случаев. В данном случае надежность выборки повышается, но увеличивается размер выборки.
Самое сложное при определении размера выборки – поиск компромисса между требуемой точностью и стоимостью сбора данных. Этот процесс усложняется тем, что увеличение размера выборки в четыре раза приводит к увеличению точности лишь в два раза (соответствует квадратному корню от величины прироста выборки).
Кейс: определение размера выборки для оценки потенциала рынка продаж столичной недвижимости покупателям из регионов
В ноябре-декабре 2016 года мы провели исследование спроса на квартиры в новостройках Москвы и Санкт-Петербурга со стороны жителей разных городов России. Исследование включало в себя три метода сбора данных: массовый репрезентативный опрос населения в возрасте от 20 до 60 лет (проводился с использованием технологии CATI), а также серию экспертных интервью с риэлторами и глубинных интервью с потенциальными покупателями квартир.
Исследование охватывало 33 города, отличающихся повышенным спросом на петербургскую и московскую недвижимость. Плановая выборка исследования, рассчитанная по формулам, составила 21 500 респондентов. Этот объем значительно больше «стандартного» объема выборки, используемого в маркетинговых исследованиях. С чем же связан такой большой размер выборки?
Все дело в том, что клиенту были нужны оценки отдельно по каждому городу, а не просто «в целом по стране». Фактически мы работаем не с 1 выборкой, а с 33 отдельными выборками по каждому городу. Доля людей, заинтересованных в покупке квартиры в Санкт-Петербурге или Москве, была экспертно определена в рамках 5% от числа жителей опрашиваемых городов.
В зависимости от важности города для заказчика, руководитель проекта со стороны Агентства определил допустимую статистическую погрешность, в которую должны укладываться итоговые результаты. Для этого мы использовали специальный макрос в MS Excel, но эти расчеты можно также выполнить с помощью калькулятора выборки. В результате размер выборки варьировал от 500 до 1000 респондентов по каждому из городов исследования, что в сумме и дало заявленные 21 500 человек.
- Определите структуру целевой группы. Планируете ли вы анализировать отдельные подгруппы или достаточно будет анализа по выборке в целом?
- Определите желаемую точность данных. Например, если нужно оценить динамику рыночной доли за год, подставьте в специальный калькулятор примерное значение доли и «поиграйте» с разными объемами выборки.
- Найдите баланс между стоимостью сбора данных (прямо пропорциональна объему выборки) и требуемой точностью.