|
Идентификация объектов генеральной совокупности |
|||||||||
|
Выбор метода обследования |
|||||||||
|
Сплошное обследование |
Выборочное обследование |
||||||||
|
Выбор процедуры формирования выборки |
Расчет объема выборки |
||||||||
|
Реализация плана выборки |
|||||||||
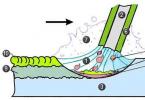
Рис. 4.3. Планирование выборки
Планирование выборки включает следующие процедуры (рис. 4.3):
Выделение объектов генеральной совокупности.
Определение метода обследования.
Определение процедуры формирования выборки.
Определение объема выборки.
Выделение объектов генеральной совокупности
Генеральная совокупность - это множество всех единиц, являющихся объектами исследования.
На этом этапе подготовки исследования необходимо определить, какие субъекты составляют исследуемую генеральную совокупность. Как правило, субъекты, входящие в генеральную совокупность, неоднородны, поэтому при определении типичных представителей объекта исследования некоторые группы могут быть упущены. Особенно сложно представить все элементы генеральной совокупности, состоящей из организаций, поскольку не все фирмы афишируют свою деятельность. В качестве генеральной совокупности могут быть определены рынок в целом, сегмент рынка или целевая группа субъектов.
Определение метода обследования
В зависимости от объема генеральной совокупности и целей исследования могут быть использованы методы сплошного или выборочного обследования.
Метод сплошного обследования заключается в изучении всех единиц генеральной совокупности. Метод связан с высокими затратами на проведение исследования, его использование оправдано, например, в случае малого количества потребителей, представляющих сегмент, или в случае, когда объем покупок данного клиента составляет значительную долю от емкости рынка в целом.
Выборка - это группа объектов исследования, которая является носителем характеристик всех единиц генеральной совокупности, например группа потребителей, представляющих интересы и вкусы всего целевого рынка.
Метод выборочного обследования обеспечивает меньшую точность по сравнению с методом сплошного обследования, однако он менее трудоемок. Целесообразно использование данного метода при наличии большого числа однородных единиц генеральной совокупности.
Метод выборочного обследования предоставляет информацию о генеральной совокупности на основании обследования только ее части, поэтому данные, полученные в ходе выборочного обследования, имеют вероятностный характер. На практике это означает, что в результате исследования определяется не конкретное значение, а интервал, в котором находится искомое значение. Вероятность, с которой можно утверждать, что ошибка выборки не превысит некоторую заданную величину, называется доверительной вероятностью.
Свойство выборки отражать характеристики генеральной совокупности называется репрезентативностью. Различие между характеристиками генеральной и выборочной совокупностей называется ошибкой выборки, которая зависит от выбранной процедуры составления (формирования) выборки.
Процедуры формирования выборки
Процедура составления выборки - это последовательность отбора респондентов в выборку.
Отбор респондентов может сопровождаться систематическими и случайными ошибками. Систематические ошибки возникают при неправильно выбранной процедуре составления выборки. Случайные ошибки существуют всегда, поскольку связаны с влиянием сложно-предсказуемых факторов. Влияние случайности полностью устранить невозможно, но величину случайной ошибки можно определить с помощью статистических методов. Систематическую ошибку невозможно оценить, но можно устранить, изменив процедуру выборки.
Учитывая наличие двух типов ошибок при формировании выборки, выделяют случайные (вероятностные) и неслучайные (детерминированные) виды процедур составления выборки.
Неслучайные процедуры формирования выборки
Неслучайные процедуры составления выборки самим процессом формирования предполагают неслучайный выбор респондентов, чье мнение может отличаться от мнения генеральной совокупности в целом, порождая тем самым наличие неслучайной (систематической) ошибки данных в результатах исследования. При использовании неслучайных процедур отбор респондентов в выборку производится на основе каких-либо принятых условий, ограничивающих круг вероятных участников исследования. Например, в выборку отбираются только те респонденты, которые владеют компьютером или зашли в магазин с 10 до 11 часов.
Возможны следующие виды неслучайных выборок:
Произвольная выборка - элементы выбираются без плана, бессистемно; способ недорог и удобен, но порождает неточность и нерепрезентативность;
типовая выборка - набор ограничен лишь характерными (типичными) элементами генеральной совокупности; используется, например, при формировании фокус-групп; требует, однако, наличия сведений о типичности изучаемых объектов;
квотированная выборка - структура выборки строится по аналогии с распределением определенных признаков в генеральной совокупности; от каждой группы генеральной совокупности отбираются участники исследования, количество которых пропорционально представительству группы в генеральной совокупности.
Случайные процедуры формирования выборки
При формировании случайной выборки применяют следующие процедуры.
простая выборка - элементы выбираются с помощью случайных чисел; при данном подходе предполагается, что для всех единиц генеральной совокупности вероятность быть избранной в выборочную совокупность одинакова (значение вероятности равняется отношению объема выборки к объему генеральной совокупности). Метод очень трудоемок и обязывает иметь список всех единиц генеральной совокупности;
систематическая (механическая) выборка - первый элемент выбирается с помощью случайных чисел, остальные элементы выборки отбираются через равные интервалы (интервал скачка), которые равны отношению объема генеральной совокупности к объему выборки. Данный порядок формирования выборки значительно упрощает процедуру, однако может внести искажения в структуру выборки, если генеральная совокупность упорядочена по какому-либо признаку.
Если генеральная совокупность упорядочена по существенному признаку (признак считается существенным, если он определяет состояние исследуемого показателя), то для уменьшения искажений выборочной характеристики следует отбирать единицы выборки из середины установленного интервала. Аналогично поступают и в том случае, когда генеральная совокупность упорядочена по второстепенному признаку, частично влияющему на изучаемый объект.
Если генеральная совокупность упорядочена по нейтральному признаку (который не оказывает влияния на поведение изучаемого объекта), то допустимо включение в выборку любой единицы генеральной совокупности из установленного интервала;
Стратифицированная (типическая или групповая) выборка - генеральная совокупность делится на группы с набором определенных признаков (сегменты или страты), в каждой из которой с помощью случайного отбора формируется своя выборка; весовой коэффициент каждой страты в общем объеме выборки соответствует ее удельному весу в генеральной совокупности; кластерная (серийная) выборка - генеральная совокупность делится на идентичные группы (гнезда, клумбы или кластеры). Кластеры должны быть по возможности однотипными, состав кластера должен быть подобен генеральной совокупности. Случайным образом из генеральной совокупности отбираются несколько групп, которые подвергаются сплошному обследованию (одноступенчатый подход). Возможен и двухступенчатый подход, когда первоначально формируется выборка из кластеров, из нее случайным образом отбираются единицы исследования (т. е. единица выборки предыдущей стадии становится генеральной совокупностью для последующей). Недостаток этой процедуры формирования выборки - кластеры могут быть неоднородны между собой, однако эта процедура проста и экономична.
Многоступенчатые выборки
Любой тип выборки может быть как одно-, так и многоступенчатым. Многоступенчатая выборка применяется в тех случаях, когда извлечь выборку из генеральной совокупности прямым путем затруднительно, при этом все единицы отбора на каждой ступени равноценны для обследования.
Многоступенчатый отбор, соединяющий различные процедуры формирования выборки, делает выборку комбинированной. Такой вариант формирования выборки позволяет добиться наиболее рациональных и экономичных условий сбора данных в соответствии с поставленными задачами.
Определение объема выборки
Определение размера выборки является некоторым компромиссом между теорией о точности результатов исследования и возможностью ее практической реализации по объему затрат на сбор информации.
Наиболее применимы следующие методы определения объема выборки:
1. Произвольный метод расчета; в этом случае объем выборки определяется на уровне 5-10 % от генеральной совокупности.
Традиционный метод расчета; связан с проведением периодических ежегодных исследований, охватывающих, например, 500, 1000 или 1500 респондентов.
Статистический метод расчета; основывается на определении статистической надежности информации.
Метод расчета с помощью номограмм.
Эмпирический метод; в этом случае выборка считается достаточной, когда все новые сведения вносят лишь незначительные изменения (которыми можно пренебречь) в уже собранные результаты исследования.
Затратный метод; основан на размере расходов, которые допустимо затратить на проведение исследования.
Статистический метод расчета объема выборки
На объем статистической выборки влияют следующие факторы:
Наличие сведений об объеме генеральной совокупности и степени ее однородности.
Требуемая точность результатов, регулируемая величиной максимально допустимой ошибки репрезентативности и величиной доверительной вероятности, с которой делается заключение о достоверности результатов исследования.
Наличие сведений о средних показателях генеральной совокупности по исследуемому признаку или об интервале варьирования признака(дисперсии).
Возможность повторного попадания единицы генеральной совокупности в выборку.
При определении объема выборки для больших совокупностей (когда объем выборки составляет менее 5% генеральной совокупности) могут использоваться следующие формулы:
а) повторная выборка (при возможности повторного попадания единицы генеральной совокупности в выборку) при неизвестном объеме генеральной совокупности, но известном распределении контролируемого признака:
где t - нормированное отклонение, которое определяется по выбранному уровню доверительной вероятности (при 95% доверительной вероятности t = 1,96; при 99% доверительной вероятности t = 2,58); р - найденная вариация генеральной совокупности, в % или в долях; q = 100 - р; Д - допустимая ошибка, в % или в долях;
б) повторная выборка при известной дисперсии изучаемого признака (о):

в) бесповторная выборка (при исключении возможности повторного попадания единицы генеральной совокупности в выборку) при известном объеме генеральной совокупности и известном распределении контролируемого признака:

где N - ;
г) бесповторная выборка при известной дисперсии изучаемого признака:

Выборка признается малой, если ее объем превышает 5% генеральной совокупности, в этом случае объем выборки может быть откорректирован:

где п" - объем выборки для малой совокупности, п - объем статистической выборки, N - объем генеральной совокупности.
Расчет статистической выборки при нормированном отклонении t = 2 и допустимой ошибке 5% (см. табл. 4.2) показывает, что для больших совокупностей объем выборки может быть определен любым способом, поскольку используемые практические приемы приводят скорее к завышению объема обследуемой совокупности.
Таблица 4.2 Зависимость размера выборки от величины генеральной совокупности*
|
Объем генеральной совокупности |
|||||||||
|
Объем выборки |
* при нормированном отклонении t = 2 и допустимой ошибке 5%.
Из табл. 4.2 видно, что при размере генеральной совокупности более 5000 ее величина не влияет на размер выборки, поэтому формула может принять следующий вид (величиной 1/ N можно пренебречь):
![]() (4.6)
(4.6)
Например, из проведенных ранее исследований известно, что распределение ответов на интересующий исследователя вопрос (например о статусе пользователя) составило 60% и 40% (60% респондентов ответили утвердительно на вопрос о пользовании продуктом и 40% - отрицательно). Доля целевых респондентов в общем объеме респондентов составляет 70%. Для более детального анализа необходимо получить 100 положительных ответов. Чтобы получить этот результат, требуется опросить 238 человек:

Таким образом, при отсутствии точной информации о размере и характеристиках генеральной совокупности (при условии, что она не менее 5000) достаточно включить в выборку 400 ее представителей. Однако следует учесть, что если мы собираемся контролировать структуру выборки по нескольким параметрам, то объем выборки будет гораздо больше. Г. А. Черчилль в своей работе «Маркетинговые исследования» приводит на этот счет правило: «Объем выборки должен обеспечивать не менее 100 наблюдений для каждой первостепенной и не менее 20-50 наблюдений для каждой второстепенной классификационной составляющей»; также следует сделать поправку на то, что отдельные респонденты, включенные в выборку, могут оказаться вне досягаемости или отказаться участвовать в исследовании.1
Количество респондентов, которых необходимо опросить для получения необходимого количества положительных ответов на интересующий вопрос, можно рассчитать по формуле:

где П - требуемое для анализа количество положительных ответов; Pj - доля положительных ответов; Р 2 - доля целевых групп, рассчитываемая как произведение всех долей респондентов, удовлетворяющих установленным требованиям (возраст, пол, статус пользователя и т. д.).
Использование номограмм для расчета объема выборки
Стремление упростить процедуру расчета объема выборки приводит к созданию таблиц, шкал или программ, которые ориентированы на обеспечение статистической надежности информации, но при этом не обременяют пользовагеля знаниями специальных формул из области статистики. Например, существует калькулятор выборки (www. shortway. to/few/calculator, htm), на сайте Gallup (www. gallup. ru) можно найти таблицу, связывающую показатели размера выборки, распределения ответов с величиной стандартной ошибки (табл. 4.3).
Таблица 4.3 Взаимосвязь показателей размера выборки, распределения ответов и стандартной ошибки
|
Распределение ответов, |
Размер выборки, |
|||||||
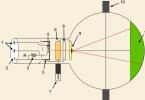
Номограмма является графическим способом определения размера выборки. Номограмма включает три шкалы (рис. 4.4). На шкале слева устанавливается разметка показателя среднеквадратического отклонения или распределения доли признака. На правой шкале наносится разметка точности измерения в виде допустимой ошибки (половины интервала) при заданной доверительной вероятности 95 или 99%. На средней шкале делается разметка, соответствующая требуемому объему выборки. На правой и левой шкалах делаются отметки на уровне желаемых значений показателей (доли признака и допустимой ошибки). Линейкой эти две отметки соединяются, на пересечении линейки со средней шкалой делается отметка, соответствующая тому объему выборки, который отвечает пожеланиям исследователя.
Рис. 4.4. Номограмма для определения объема выборки (доверительная вероятность 95%)"
4.5. Определение объема выборки
Процедура составления плана выборки включает последовательное решение трех следующих задач:
Определение объекта исследования;
Определение структуры выборки;
Определение объема выборки.
Как правило, объект маркетингового исследования представляет собой совокупность объектов наблюдения, в качестве которых могут выступать потребители, сотрудники компании, посредники и т.д. Если эта совокупность настолько малочисленна, что исследовательская группа располагает необходимыми трудовыми, финансовыми и временными возможностями для установления контакта с каждым из ее элементов, то вполне реально проведение сплошного исследования всей совокупности. В этом случае, определив объект исследования, можно приступать к следующей процедуре (выбору метода сбора данных, орудия исследования и способа связи с аудиторией).
Однако на практике очень часто не представляется возможным или целесообразным проведение сплошного исследования всей совокупности. Для этого могут быть следующие причины:
Невозможность установления контакта с некоторыми элементами совокупности;
Неоправданно большие расходы на проведение сплошного исследования или наличие финансовых ограничений, не позволяющих проведение сплошного исследования;
Сжатые сроки, отведенные для исследования, обусловленные утратой со временем актуальности информации или другими причинами и не позволяющие осуществить сбор, систематизацию и анализ обширных данных для всей совокупности.
Поэтому большие и разбросанные совокупности часто изучаются с помощью выборки, под которой, как известно, понимается часть совокупности, призванная олицетворять совокупность в целом.
Точность, с которой выборка отражает совокупность в целом, зависит от структуры и размера выборки .
Различают два подхода к структуре выборки - вероятностный и детерминированный.
Вероятностный подход к структуре выборки предполагает, что любой элемент совокупности может быть выбран с определенной (не нулевой) вероятностью. Существуют различные виды выборок, основанных на теории вероятностей (типическая, гнездовая и др.). Наиболее простой и распространенной на практике является простая случайная выборка, при которой каждый элемент совокупности имеет равную вероятность выбора для исследования.
Вероятностная выборка более точна, позволяет исследователю оценить степень достоверности собранных им данных, хотя она сложней и дороже, чем детерминированная.
Детерминированный подход к структуре выборки предполагает, что выбор элементов совокупности производится методами, основанными либо на соображениях удобства, либо на решении исследователя, либо на контингентных группах.
на соображениях удобства , состоит в выборе любых элементов совокупности исходя из простоты установления контакта с ними. Несовершенство этого метода обусловлено, возможно, низкой репрезентативностью полученной выборки, т.к. удобные для исследователя элементы совокупности могут быть недостаточно характерными представителями совокупности в силу неслучайного и необоснованного их отбора.
Однако, с другой стороны, простота, экономичность и оперативность исследования, проводимого этим методом, снискали ему довольно широкое распространение на практике и, прежде всего при проведении предварительных исследований, направленных на уточнение основных проблем.
Метод формирования выборки, основанный на решении исследователя , состоит в выборе элементов совокупности, которые, по его мнению, являются ее характерными представителями. Этот метод является более совершенным, чем предыдущий, поскольку в его основе лежит ориентировка на характерных представителей исследуемой совокупности, хотя и подбираемых на основе субъективных представлений исследователей о ней.
Метод формирования выборки, основанный на контингентных нормах , состоит в выборе характерных элементов совокупности в соответствии с полученными ранее характеристиками совокупности в целом. Эти характеристики могут быть получены путем проведения предварительных исследований и в отличие от предыдущего метода не носят субъективного характера. Поэтому данный метод является более совершенным, он позволяет получить выборочные совокупности не менее представительные, чем вероятностные выборки при значительно меньших затратах на проведение обследования.
Выбрав структуру выборки (подход к ее формированию, вид вероятностной или метая формирования детерминированной выборки), исследователю предстоит определить объем, т.е. количество элементов выборочной совокупности.
Объем выборки определяет достоверность информации , полученной в результате ее исследования, а также необходимые для проведения исследования затраты. Объем выборки зависит от уровня однородности или разновидности изучаемых объектов.
Чем больше объем выборки, тем выше ее точность и больше затраты на проведения ее обследования. При вероятностном подходе к структуре выборки ее объем может быть определен с помощью известных статистических формул, на основе заданных требований к ее точности.
На практике используется несколько подходов к определению объема выборки:
1. Произвольный подход основан на применении «правила большого пальца». Например, бездоказательно принимается, что для получения точных результатов выборка должна составлять 5 % от совокупности. Данный подход является простым и легким в исполнении, однако не представляется возможным установить точность полученных результатов. При достаточно большой совокупности он к тому же может быть и весьма дорогим.
Объем выборки может быть установлен исходя из неких заранее оговоренных условий. К примеру, заказчик маркетингового исследования знает, что при изучении общественного мнения выборка обычно составляет 1000-1200 человек, поэтому он рекомендует исследователю придерживаться данной цифры. В случае, если на каком-то рынке проводятся ежегодные исследования, то в каждом году используется выборка одного и того же объема. В отличие от первого подхода здесь при определении объема выборки используется известная логика, которая, однако, является весьма уязвимой.
Например, при проведении определенных исследований может потребоваться точность меньше, чем при изучении общественного мнения, да и объем совокупности может быть во много раз меньше, нежели при изучении общественного мнения. Таким образом, данный подход не принимает в расчет текущие обстоятельства и может быть достаточно дорогим.
В ряде случаев в качестве главного аргумента при определении объема выборки используется стоимость проведения обследования. Так, в бюджете маркетинговых исследований предусматриваются затраты на проведение определенных обследований, которые нельзя превышать. Очевидно, что ценность получаемой информации не принимается в расчет. Однако в ряде случаев и малая выборка может дать достаточно точные результаты.
Представляется разумным учитывать затраты не абсолютным образом, а по отношению к полезности информации, полученной в результате проведенных обследований. Заказчик и исследователь должны рассмотреть различные объемы выборки и методы сбора данных, затраты, учесть другие факторы
2. Объем выборки от уровня доверительного интервала допустимой ошибки, каковая, как уже говорилось, задается целесообразной точностью итоговых обобщений: от повышенной до ориентировочной. Однако здесь имеются в виду так называемые случайные ошибки, связанные с природой любых статистических погрешностей. Именно они и вычисляются как ошибки репрезентативности вероятностных выборок.
В. И. Паниотто приводит следующие расчеты репрезентативной выборки с допущением 5-процентной ошибки (табл. 4.2).
Таблица 4.2
Расчетная таблица выборки
Для совокупности более 100000 выборка составляет 400 единиц. Если же иметь в виду генеральные совокупности численностью от 5 тыс. и больше, то, по расчетам того же автора, можно указать величины фактической ошибки выборки в зависимости от ее объема, что для нас весьма важно, памятуя, что величина допустимой ошибки зависит от цели исследования и необязательно должна приближаться к 5-процентному уровню.
Таблица 4.3
Расчетная таблица
Наряду со случайными возможны ошибки систематического характера. Они зависят от организации выборочного обследования. Это разнообразные смещения выборки в сторону одного из полюсов выборочного параметра.
3. Объем выборки на основе статистического анализа . Этот подход основан на определении минимального объема выборки исходя из определенных требований к надежности и достоверности получаемых результатов. Он также используется при анализе полученных результатов для отдельных подгрупп, формируемых в составе выборки по полу, возрасту, уровню образования и т.п. Требования к надежности и точности результатов для отдельных подгрупп диктуют определенные требования к объему выборки в целом.
Наиболее теоретически обоснованный и корректный подход к определению объема выборки основан на расчете достоверных интервалов. Понятие вариации характеризует величину несхожести (схожести) ответов респондентов на определенный вопрос. В более строгом плане вариацией значений какого-либо признака в совокупности называется различие его значений у разных единиц данной совокупности в один и тот же период или момент времени. Результаты ответов на вопросы опроса обычно представляются в форме кривой распределения (рис. 4.1). При высокой схожести ответов говорят о малой вариации (узкая кривая распределения) и при низкой схожести ответов – о высокой вариации (широкая кривая распределения).
В качестве меры вариации обычно принимается среднее квадратическое отклонение, которое характеризует среднее расстояние от средней оценки ответов каждого респондента на определенный вопрос.

Малая вариация
Высокая вариация
Рис. 4.1. Вариация и кривые распределения
Поскольку все маркетинговые решения принимаются в условиях неопределенности, то это обстоятельство целесообразно учесть при определении объема выборки. Так как определение исследуемых величин для совокупности в узком осуществляется на основе выборочной статистики, то следует установить диапазон (доверительный интервал), в который, как ожидается, попадут оценки для совокупности в целом, и ошибку их определения.
Доверительный интервал – это диапазон, крайним точкам которого соответствует определенный процент определенных ответов на какой-то вопрос. Доверительный интервал тесно связан со средним квадратическим отклонением изучаемого признака в генеральной совокупности: чем оно больше, тем шире должен быть доверительный интервал, чтобы включить в свой состав определенный процент ответов.
Доверительный интервал, равный или 95 %, или 99 %, является стандартным при проведении маркетинговых исследований. Ни одна фирма не проводит маркетинговых исследований, формируя несколько выборок. И математическая статистика дает возможность получить некую информацию о выборочном распределении, владея только данными о вариации единственной выборки.
Индикатором степени отличия оценки, истинной для совокупности в целом, от оценки, которая ожидается для типичной выборки, является средняя квадратическая ошибка. Причем, чем больше объем выборки, тем меньше ошибка. Высокое значение вариации обусловливает высокое значение ошибки и наоборот.
Когда на заданный вопрос существует только два варианта ответа, выраженные в процентах (используется процентная мера), объем выборки определяется по следующей формуле:

где n – объем выборки; z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности; p – найденная вариация для выборки; g – (100-р); е – допустимая ошибка.
При определении показателя вариации для определенной совокупности прежде всего целесообразно провести предварительный качественный анализ исследуемой совокупности, в первую очередь установить схожесть единиц совокупности в демографическом, социальном и других отношениях, представляющих интерес для исследователя. Возможно проведение пилотного исследования, использование результатов подобных исследований, проведенных в прошлом. При использовании процентной меры изменчивости принимается в расчет то обстоятельство, что максимальная изменчивость достигается для р = 50 %, что является наихудшим случаем. К тому же этот показатель радикальным образом не влияет на объем выборки. Учитывается также мнение заказчика исследования об объеме выборки.
Возможно определение объема выборки на основе использования средних значений, а не процентных величин.

где s – среднее квадратическое отклонение.
На практике, если выборка формируется заново и схожие опросы не проводились, то s не известно. В этом случае целесообразно задавать погрешность е в долях от среднеквадратического отклонения. Расчетная формула преобразуется и приобретает следующий вид:
 где
где  .
.
Выше шел разговор о совокупностях очень больших размеров. Однако в ряде случаев совокупности не являются большими. Обычно, если выборка составляет менее пяти процентов от совокупности, то совокупность считается большой и расчеты проводятся по вышеприведенным правилам. Если объем выборки превышает 5 % от совокупности, то последняя считается малой и в вышеприведенные формулы вводится поправочный коэффициент.
Объем выборки в данном случае определяется следующим образом:
 ,
,
Определение объема вероятностной выборки
Объем вероятностной выборки определяется по специальным формулам, в зависимости от заданной достоверности , точности исследования и дисперсии генеральной совокупности.
Теоретической основой возможности использования выборочного обследования для оценки характеристик генеральной совокупности является центральная предельная теорема .
Центральная предельная теорема гласит: для простых случайных выборок объемом n , выделенных из генеральной совокупности с истинным средним μ и дисперсией σ2 , для больших n распределение выборочных средних приближается к нормальному с центром, равным истинному среднему, и дисперсией, равной отношению дисперсии генеральной совокупности к объему выборки, то есть:
Теорема верна для любого распределения частот в генеральной совокупности, однако чем ближе распределение в генеральной совокупности к нормальному, тем меньший объем выборки необходим для достижения эквивалентной достоверности и точности исследования.
На практике исследователь формирует только одну выборку из генеральной совокупности и ему необходимо знать, какой должен быть объем выборки для соблюдения заданных параметров достоверности и точности. Формула для определения объема выборки при оценке среднего может быть выведена, исходя из положений центральной предельной теоремы, и имеет вид:
n - необходимый объем выборки;
z - количество интервалов, характеризующих требование к достоверности исследования;
H - требуемая величина точности исследования;
σ2 - дисперсия генеральной совокупности.
Рассмотрим подробнее параметры правой части уравнения.
Достоверность характеризует вероятность того, что конкретная случайная выборка адекватно отражает характеристику генеральной совокупности.
Достоверность 99% означает, что в 99 выборках из 100 средняя генеральной совокупности будет входить в интервал средней, полученной в результате выборочного исследования.
Пример . Например, проведено три независимых выборочных исследования уровня доходов населения в конкретном регионе. Получены следующие данные о среднем уровне дохода: 300 10 грн., 310 10 грн., 305 10 грн., истинное среднее значение равно 302 грн.
Как видим, истинное среднее значение входит во все три интервала.
При достоверности 99% и заданной точности 10 грн. в 99 выборках из ста среднее выборки будет находиться в интервале от 292 до 312 грн. В одном случае из ста мы получим результат либо ниже 292 грн., либо больше 312 грн. Результаты такого исследования будут недостоверны, т.к. среднее генеральной совокупности не будет входить в коридор полученной в результате выборочного исследования средней величины.
В представленной формуле достоверность характеризуется величиной z, которая определяется по таблице z-распределения в зависимости от заданной достоверности в процентах.
Приведем соответствие только для некоторых типичных вероятностей: 68,26% (z=1), 95,45% (z=2), 99,73% (z=3).
z-распределение – Стандартное нормальное (Z) распределение
Значение z (z value) – количество стандартных ошибок, на которое точка удалена от среднего значения.
Вместо таблицы для вычисления вероятности попадания случайной величины в отмеченный (заштрихованный) диапазон

можно воспользоваться следующей формулой EXCEL:
2*НОРМСТРАСП(z)-1
подставив в нее требуемое значение z. Например:
Точность определяется исследователем, исходя из конкретной поставленной задачи.
Если исследуемая величина является абсолютной, то и точность должна быть представлена абсолютной, а не относительной величиной. При определении процентов (долей) точность определяется в процентах.
При определении точности исследователь должен учитывать возможное исследование динамики показателя.
Пример . Например, если при точности 10 грн. результаты исследования в прошлом году определили средний доход в 300 грн., а в текущем 305 грн., делать выводы об увеличении дохода некорректно, т.к. величина изменения входит в заданный интервал точности (менее 10 грн.).
Наиболее сложным при расчете объема выборки является определение дисперсии . При оценке среднего возникают два основных случая:
1) дисперсия генеральной совокупности известна на основании предыдущих исследований;
2) дисперсия генеральной совокупности неизвестна.
Возможность использования дисперсии, полученной в результате предыдущих исследований , основана на том, что этот параметр генеральной совокупности более инерционен, чем среднее. Другими словами, он изменяется медленнее и, следовательно, если вы, к примеру, ежегодно изучаете уровень дохода населения, то можете использовать величину дисперсии, полученную в прошлогодних исследованиях.
Пример расчета объема выборки .
Во-первых, на объем выборки влияет уровень доверительности α, по которому при помощи специальной таблицы определяется нормированное отклонение z. Например, для случая α = 99% по таблице найдем z = 2,58.
Во-вторых, оказывает влияние уровень (коэффициент) вариации . Примем, например, коэффициент вариации равным = 50%.
В-третьих, на объем выборки влияет требуемая точность (допустимая ошибка)
Если об уровне генеральной Вам ничего неизвестно , то для оценки уровня дисперсии возможно применение правила трех сигм . При нормальном распределении 99% параметров характеристики должно находиться в интервале плюс-минус три сигмы от истинной средней. Проводя исследование, Вы должны оценить типичный верхний (b ) и нижний (a ) уровни параметра , интервал между которыми и составляет шесть сигм. Величина сигмы составит разницу уровней параметра деленную на 6.
Дисперсия или вариация var:
![]() ,
,
где b, a – соответственно верхнее и нижнее значение параметра.
Сигма – это среднеквадратическое отклонение (стандартное отклонение):
![]() .
.
Пример . Например, при исследовании уровня дохода нижнее значение параметра принимается на уровне 0 грн., а верхнее, предположим, на уровне 6000 грн. В этом случае значение среднеквадратичного (стандартного) отклонения составит: (6000-0)/6=1000.
Следует заметить, что если исследователь действительно готов к проведению исследования, то определение типичных нижней и верхней границы параметра не представляют особой сложности.
При работе с маркетинговыми шкалами принимаемая величина дисперсии зависит от количества точек шкалы и типа распределения частот.
Наихудшим в маркетинговых исследованиях (соответствующей максимальной дисперсии) считается равномерное распределение ответов между точками шкалы. Наилучшим – нормальное с максимальной частотой ответов в середине шкалы.
Таблица 5.1. Типовые диапазоны дисперсий в зависимости от количества точек шкалы
Нижние уровни диапазона соответствуют нормальному распределению частот, верхние – равномерному.
Рассмотренная выше формула определения объема выборки применяется при оценке средних величин .
Если исследователь работает с процентами или долями , то формула трансформируется в следующий вид:
![]() ,
,
где р - доля людей, положительно или отрицательно отвечающих на поставленный вопрос.
При работе с процентами в формулу вместо единицы подставляется 100.
Очевидно, что максимальное значение множителя (1-р)р имеет место при одинаковой доле положительных и отрицательных ответов и составляет при работе с долями 0,25, а при работе с процентами – 2500. Однако результат при работе с долями или процентами будет эквивалентен, так как численное значение квадрата точности, стоящее в знаменателе, также будет отличаться в 10000 раз.
За исключением случаев, когда применяется коэффициент окончательной коррекции совокупности. Возможно, это кажется невероятным, но если подумать, в этом утверждении есть смысл. Например, если исследуемые характеристики всех элементов совокупности идентичны, то выборки, состоящей из одного элемента, вполне достаточно, чтобы рассчитать среднее. Это также правильно, если совокупность состоит из 50, 500, 5000 или 50000 элементов.
В то же время изменчивость характеристик совокупности напрямую влияет на объем выборки. Эта изменчивость учитывается при вычислении объема выборки с помощью дисперсии совокупности σ2 или дисперсии выборки s2.
Пример (Н.Б.Сафронова, И.Е.Корнеева). Проведем расчет выборки для маркетингового исследования, посвященного узнаваемости потребителями торговой марки. Значение вероятности P = 0,954, предельно допустимая ошибка данного исследования не должна превышать 5%. Какое количество респондентов необходимо опросить для решения этой проблемы в порядке случайной повторной выборки притом, что данные о распределении признаков отсутствуют?
Решение . Так как доля признака неизвестна, допустим, что 50% потребителей знают торговую марку, а 50% – нет. Используем формулу расчета выборки с учетом доли признака:
![]() =
= ![]() =400 чел.
=400 чел.
Более сложные методы расчета объема выборки необходимы при использовании в процессе анализа двойной или тройной табуляции. Это связано с тем, что достоверность и точность, достигаемая при рассчитанном объеме выборки, для выборки в целом, не достигается для отдельных ее частей, на которые разбивается выборка в процессе табуляции.
Пример . Например, при определении среднего уровня дохода населения определенный объем выборки может быть достаточен, но он недостаточен для определения среднего уровня дохода мужчин и женщин (при заданных точности и достоверности). Это легко понять, потому что количество мужчин и женщин, принявших участие в опросе отдельно, меньше количества всех респондентов. Зная, однако, соотношение мужчин и женщин, легко определить, с какой точностью рассчитан уровень среднего дохода для каждой из рассматриваемых групп.
Определение объема выборки: среднее
Метод, использованный для создания доверительного интервала, можно модифицировать так, чтобы определить объем выборки с учетом желательного доверительного интервала. Предположим, что вы хотите рассчитать ежемесячный расход семьи на покупки в универмаге более точно, так, чтобы полученный результат находился в пределах ±5,00 долларов от истинного среднего значения исследуемой совокупности. Каким должен быть объем выборки? В табл. 12.2 приведен необходимый перечень действий, который вы должны выполнить.
1. Определите степень точности. Это максимально допустимое различие (D) между выборочным средним и генеральным средним. В нашем примере D = ±5,00 долларов.
2. Укажите уровень достоверности. Предположим, что желательный уровень достоверности 95%.
3. Определите значение г, связанное с данным уровнем достоверности, воспользовавшись табл. 2 в Приложении "Статистические таблицы". При 95%-ном уровне достоверности вероятность того, что среднее значение генеральной совокупности выйдет за пределы одностороннего интервала, равна 0,025 (0,05/2). Соответствующее значение г составляет 1,96.
4. Определите стандартное отклонение среднего генеральной совокупности. Его можно получить из вторичных источников или рассчитать, проведя пилотное исследование. Кроме того, стандартное отклонение можно установить на основе мнения исследователя. Например, диапазон нормально распределенной переменной примерно укладывается в шесть стандартных отклонений (по три слева и справа от среднего значения). Таким образом, можно рассчитать среднеквадратичное отклонение, разделив величину всего диапазона на 6. Исследователь часто может определить размеры диапазон, исходя из собственного понимания анализируемых явлений.
5. Определите объем выборки, воспользовавшись формулой стандартной ошибки среднего:

В нашем примере
![]() (округленное в большую сторону до ближайшего целого числа).
(округленное в большую сторону до ближайшего целого числа).
неквадратичное отклонение выборки 5, равное 50,00. Тогда исправленный доверительный интервал составит

Обратите внимание, что полученный доверительный интервал уже предполагаемого. Это вызвано тем, что среднеквадратичное отклонение совокупности завышено на основании выборочных характеристик.
8. Иногда точность определена в относительных, а не абсолютных показателях. Другими словами, может быть известно, что результат вычисления должен составить плюс-минус R% от среднего. Это означает, что D = rm .
В этом случае объем выборки можно определить как
![]()
Объем генеральной совокупности N не влияет на объем выборки напрямую, за исключением случаев, когда применяется коэффициент окончательной коррекции совокупности. Возможно, это кажется невероятным, но если подумать, в этом утверждении есть смысл. Например, если исследуемые характеристики всех элементов совокупности идентичны, то выборки, состоящей из одного элемента, вполне достаточно, чтобы рассчитать среднее. Это также правильно, если совокупность состоит из 50,500,5000 или 50000 элементов. В то же время изменчивость характеристик совокупности напрямую влияет на объем выборки. Эта изменчивость учитывается при вычислении объема выборки с помощью дисперсии совокупности s2 или дисперсии выборки s2.
Один из главных компонентов тщательно продуманного исследования – определение выборки и что такое репрезентативная выборка. Это как в примере с тортом. Ведь не обязательно съедать весь десерт, чтобы понять его вкус? Достаточно небольшой части.
Так вот, торт – это генеральная совокупность (то есть все респонденты, которые подходят для опроса). Она может быть выражена территориально, например, лишь жители Московской области. Гендерно – только женщины. Или иметь ограничения по возрасту – россияне старше 65 лет.
Высчитать генеральную совокупность сложно: нужно иметь данные переписи населения или предварительных оценочных опросов. Поэтому обычно генеральную совокупность «прикидывают», а из полученного числа высчитывают выборочную совокупность или выборку .
Что такое репрезентативная выборка?
Выборка – это чётко определенное количество респондентов. Её структура должна максимально совпадать со структурой генеральной совокупности по основным характеристикам отбора.
 Например, если потенциальные респонденты – всё население России, где 54% — это женщины, а 46% — мужчины, то выборка должна содержать точно такое же процентное соотношение. Если совпадение параметров происходит, то выборку можно назвать репрезентативной. Это значит, что неточности и ошибки в исследовании сводятся к минимуму.
Например, если потенциальные респонденты – всё население России, где 54% — это женщины, а 46% — мужчины, то выборка должна содержать точно такое же процентное соотношение. Если совпадение параметров происходит, то выборку можно назвать репрезентативной. Это значит, что неточности и ошибки в исследовании сводятся к минимуму.
Объем выборки определяется с учётом требований точности и экономичности. Эти требования обратно пропорциональны друг другу: чем больше объем выборки, тем точнее результат. При этом чем выше точность, тем соответственно больше затрат необходимо на проведение исследования. И наоборот, чем меньше выборка, тем меньше на неё затрат, тем менее точно и более случайно воспроизводятся свойства генеральной совокупности.
Поэтому для вычисления объема выбора социологами была изобретена формула и создан специальный калькулятор :
Доверительная вероятность и доверительная погрешность
Что означают термины «доверительная вероятность » и «доверительная погрешность »? Доверительная вероятность – это показатель точности измерений. А доверительная погрешность – это возможная ошибка результатов исследования. К примеру, при генеральной совокупности более 500 00 человек (допустим, проживающие в Новокузнецке) выборка будет равняться 384 человека при доверительной вероятности 95% и погрешности 5% ИЛИ (при доверительном интервале 95±5%).
Что из этого следует? При проведении 100 исследований с такой выборкой (384 человека) в 95 процентов случаев получаемые ответы по законам статистики будут находиться в пределах ±5% от исходного. И мы получим репрезентативную выборку с минимальной вероятностью статистической ошибки.
После того, как подсчет объема выборки выполнен, можно посмотреть есть ли достаточное число респондентов в демо-версии Панели Анкетолога . А как провести панельный опрос можно подробнее узнать .
где – среднее значение выборки, Z - значение стандартизованной нормально распределенной случайной величины, соответствующее интегральной вероятности, равной 1 – α/2 , σ - стандартное отклонение генеральной совокупности, n – объем выборки
Скачать заметку в формате или , примеры в формате
В этой формуле величина, добавляемая и вычитаемая из равна половине длины интервала. Она определяет меру неточности оценки, возникающей вследствие ошибки выборочного исследования, которая обозначается символом е и вычисляется по формуле
![]()
Решив уравнение (2) относительно n , получим:
![]()
На практике вычислить эти величины непросто. Как определить доверительный уровень и ошибку выборочного исследования? Обычно ответить на этот вопрос могут лишь эксперты в предметной области (т.е. люди, понимающие смысл оцениваемых величин). Как правило, доверительный уровень равен 95% (в этом случае Z = 1,96). Если требуется поднять доверительный уровень, обычно выбирают величину, равную 99%. Если можно ограничиться более низким доверительным уровнем, выбирают 90%. Определяя ошибку выборочного исследования, не стоит думать о ее величине (в принципе, любая ошибка нежелательна). Следует задать такую ошибку, чтобы полученные результаты допускали разумную интерпретацию.
Кроме доверительного уровня и ошибки выборочного исследования, необходимо знать стандартное отклонение генеральной совокупности. К сожалению, этот параметр почти никогда не известен. В некоторых случаях стандартное отклонение генеральной совокупности можно оценить на основе предшествующих исследований. В других ситуациях эксперт может учесть размах выборки и распределение случайной переменной. Например, если генеральная совокупность имеет нормальное распределение, ее размах приближенно равен 6σ (т.е. ±3σ в окрестности математического ожидания). Следовательно, стандартное отклонение приближенно равно одной шестой части диапазона. Если величину σ невозможно оценить таким способом, необходимо выполнить пилотный проект и вычислить стандартное отклонение по результатам.
Пример 1. Вернемся к задаче об аудиторской проверке. Предположим, что из информационной системы извлечена выборка, состоящая из 100 накладных, заполненных в течение последнего месяца. Компания желает построить интервал, содержащий математическое ожидание генеральной совокупности, доверительный уровень которого равен 95%. Как был определен объем выборки? Следует ли его уточнить?
Допустим, что после консультаций с экспертами, работающими в компании, статистики установили допустимую ошибку выборочного исследования равной ±5 долл., а доверительный уровень - 95%. Результаты предшествующих исследований свидетельствуют, что стандартное отклонение генеральной совокупности приближенно равно 25 долл. Таким образом, е = 5, σ = 25 и Z = 1,96 (что соответствует 95%-ному доверительному уровню). По формуле (3) получаем:

Следовательно, n = 96. Таким образом, объем выборки, равный 100, был выбран удачно и вполне соответствует требованиям, выдвинутым компанией.
Пример 2. Некая промышленная компания на Среднем Западе производит электрические изоляторы. Если во время работы изолятор выходит из строя, происходит короткое замыкание. Чтобы проверить прочность изолятора, компания проводит испытания, в ходе которых определяется максимальная сила, необходимая для разрушения изолятора. Сила измеряется в фунтах нагрузки, приводящей к разрушению изолятора (рис. 1, столбец А). Предположим, что нам необходимо оценить среднюю силу разрушения изолятора с точностью +25 фунтов при 95%-ном доверительном интервале для этой величины. Данные, полученные в предыдущем исследовании, свидетельствуют, что стандартное отклонение равно 100 фунтов. Определите требуемый объем выборки.
Решение. Итак, е = 25, σ =100, доверительный уровень 95% (т.е. Z = 1,96) (рис. 1).

Рис. 1. Определение объема выборки
Таким образом, n = 62 (дробные результаты, как правило, округляют с избытком до ближайшего целого).
Определение объема выборки для оценки доли признака в генеральной совокупности
Выше мы рассмотрели способ определения объема выборки для оценки математического ожидания генеральной совокупности. Предположим теперь, что нам необходимо определить долю накладных, не соответствующих правилам, принятым компанией (начальные условия см. пример 1 выше). Сколько накладных следует извлечь из информационной системы, чтобы построенный интервал имел заданный доверительный уровень? Для ответа на этот вопрос применим тот же подход, что и при определении объема выборки для оценки математического ожидания.
Ошибка выборочного исследования определяется по формуле (2). При оценке доли признака величину σ следует заменить на величину . Таким образом, формула для ошибки выборочного исследования принимает следующий вид:

Выражая n через остальные величины, получаем следующую формулу:

Таким образом, для определения объема выборки необходимо знать три параметра:
- Требуемый доверительный уровень, по которому определяется величина Z .
- Допустимую ошибку выборочного исследования е .
- Истинную долю успехов р .
На практике вычислить эти величины нелегко. Если известен доверительный уровень, можно вычислить критическое значение стандартизованного нормального распределения Z . Ошибка выборочного исследования е определяет точность, с которой оценивается доля успехов в генеральной совокупности. Третий параметр - доля успехов в генеральной совокупности р - это именно тот параметр, который нам необходимо оценить. Итак, как оценить диапазон изменения величины р по его выборочным значениям?
Существуют два способа. Во-первых, во многих ситуациях для оценки величины р можно использовать результаты предыдущих исследований. Во-вторых, если данные о предыдущих исследованиях недоступны, можно попытаться оценить параметр р так, чтобы исключить недооценку объема выборки. Обратите внимание на то, что в формуле (5) величина р(1 – р) стоит в числителе. Следовательно, необходимо найти максимальное значение этой величины. Очевидно, что оно достигается при р = 0,5.
Таким образом, если доля признака в генеральной совокупности р заранее неизвестна, для определения объема выборки следует задать р = 0,5. В этом случае объем выборки будет переоценен, что приведет к дополнительным затратам на ее создание. Если истинная доля успехов в генеральной совокупности сильно отличается от 0,5, доверительный интервал окажется значительно уже, чем требовалось. Оценка параметра р в этом случае будет весьма точной, однако за это придется заплатить дополнительными временны ми и финансовыми ресурсами.
Вернемся к задаче об аудиторской проверке. Предположим, аудитор желает построить интервал, содержащий долю ошибочных накладных, доверительный уровень которого равен 95%. Допустимая точность равна ±0,07. Результаты предыдущих проверок свидетельствуют, что доля ошибочных накладных не превышает 0,15. Таким образом, е = 0,07, р = 0,15 и Z = 1,96 (что соответствует 95%-ному доверительному уровню). По формуле (5) получаем:

Таким образом, объем выборки, равный 100, был выбран совершенно правильно и вполне соответствует требованиям, выдвинутым компанией.
Определение объема выборки, извлекаемой из конечной генеральной совокупности
Для определения объема выборки, извлеченной из конечной генеральной совокупности без возвращения, необходимо использовать поправочный коэффициент. Например, при оценке математического ожидания выборочная ошибка вычисляется по следующей формуле:
![]()
При оценке доли признака ошибка выборочного исследования равна:

Чтобы вычислить объем выборки для оценки математического ожидания или доли признака, применяются формулы:
![]()
где n 0 - объем выборки без учета поправочного коэффициента для конечной генеральной совокупности. Применение поправочного коэффициента приводит к следующей формуле:
![]()
Используются материалы книги Левин и др. Статистика для менеджеров. – М.: Вильямс, 2004. – с. 471–476
Для определения размера выборки используется величина Z , а не t , поскольку для вычисления критического значения t размер выборки необходимо знать заранее. В большинстве случаев размеры выборки позволяют хорошо аппроксимировать t -распределение стандартизованным нормальным распределением.
Интервал c доверительным уровнем 95% делится на две равные части. Первая часть лежит слева от математического ожидания генеральной совокупности, а вторая - справа. Значение величины Z, соответствующей вероятности 2,5% (площади 0,025), равно –1,96, а значение величины Z, соответствующей суммарной площади 0,975, равно +1,96. Для расчета удобно воспользоваться функцией Excel Z =НОРМ.СТ.ОБР(р), где р – вероятность, подставляя значения р 1 = 2,5% и р 2 = 97,5%
Статистическая совокупность - множество единиц, обладающих массовостью, типичностью, качественной однородностью и наличием вариации.
Статистическая совокупность состоит из материально существующих объектов (Работники, предприятия, страны, регионы), является объектом .
Единица совокупности — каждая конкретная единица статистической совокупности.
Одна и таже статистическая совокупность может быть однородна по одному признаку и неоднородна по другому.
Качественная однородность — сходство всех единиц совокупности по какому-либо признаку и несходство по всем остальным.
В статистической совокупности отличия одной единицы совокупности от другой чаще имеют количественную природу. Количественные изменения значений признака разных единиц совокупности называются вариацией.
Вариация признака — количественное изменение признака (для количественного признака) при переходе от одной единицы совокупности к другой.
Признак - это свойство, характерная черта или иная особенность единиц, объектов и явлений, которая может быть наблюдаема или измерена. Признаки делятся на количественные и качественные. Многообразие и изменчивость величины признака у отдельных единиц совокупности называется вариацией .
Атрибутивные (качественные) признаки не поддаются числовому выражению (состав населения по полу). Количественные признаки имеют числовое выражение (состав населения по возрасту).
Показатель — это обобщающая количественно качестванная характеристика какого-либо свойства единиц или совокупности в цельм в конкретных условиях времени и места.
Система показателей — это совокупность показателей всесторонне отражающих изучаемое явление.
Например, изучается зарплата:- Признак — оплата труда
- Статистическая совокупность — все работники
- Единица совокупности — каждый работник
- Качественная однородность — начисленная зарплата
- Вариация признака — ряд цифр
Генеральная совокупность и выборка из нее
Основу составляет множество данных, полученных в результате измерения одного или нескольких признаков. Реально наблюдаемая совокупность объектов, статистически представленная рядом наблюдений случайной величины , является выборкой , а гипотетически существующая (домысливаемая) — генеральной совокупностью . Генеральная совокупность может быть конечной (число наблюдений N = const ) или бесконечной (N = ∞ ), а выборка из генеральной совокупности — это всегда результат ограниченного ряда наблюдений. Число наблюдений , образующих выборку, называется объемом выборки . Если объем выборки достаточно велик (n → ∞ ) выборка считается большой , в противном случае она называется выборкой ограниченного объема . Выборка считается малой , если при измерении одномерной случайной величины объем выборки не превышает 30 (n <= 30 ), а при измерении одновременно нескольких (k ) признаков в многомерном пространстве отношение n к k не превышает 10 (n/k < 10) . Выборка образует вариационный ряд , если ее члены являются порядковыми статистиками , т. е. выборочные значения случайной величины Х упорядочены по возрастанию (ранжированы), значения же признака называются вариантами .
Пример . Практически одна и та же случайно отобранная совокупность объектов — коммерческих банков одного административного округа Москвы, может рассматриваться как выборка из генеральной совокупности всех коммерческих банков этого округа, и как выборка из генеральной совокупности всех коммерческих банков Москвы, а также как выборка из коммерческих банков страны и т.д.
Основные способы организации выборки
Достоверность статистических выводов и содержательная интерпретация результатов зависит от репрезентативности выборки, т.е. полноты и адекватности представления свойств генеральной совокупности, по отношению к которой эту выборку можно считать представительной. Изучение статистических свойств совокупности можно организовать двумя способами: с помощью сплошного и несплошного . Сплошное наблюдение предусматривает обследование всех единиц изучаемой совокупности , а несплошное (выборочное) наблюдение — только его части.
Существуют пять основных способов организации выборочного наблюдения:
1. простой случайный отбор , при котором объектов случайно извлекаются из генеральной совокупности объектов (например с помощью таблицы или датчика случайных чисел), причем каждая из возможных выборок имеют равную вероятность. Такие выборки называются собственно-случайными ;
2. простой отбор с помощью регулярной процедуры осуществляется с помощью механической составляющей (например, даты, дня недели, номера квартиры, буквы алфавита и др.) и полученные таким способом выборки называются механическими ;
3. стратифицированный отбор заключается в том, что генеральная совокупность объема подразделяется на подсовокупности или слои (страты) объема так что . Страты представляют собой однородные объекты с точки зрения статистических характеристик (например, население делится на страты по возрастным группам или социальной принадлежности; предприятия — по отраслям). В этом случае выборки называются стратифицированными (иначе, расслоенными, типическими, районированными );
4. методы серийного отбора используются для формирования серийных или гнездовых выборок . Они удобны в том случае, если необходимо обследовать сразу "блок" или серию объектов (например, партию товара, продукцию определенной серии или население при территориально-административном делении страны). Отбор серий можно осуществить собственно-случайным или механическим способом. При этом проводится сплошное обследование определенной партии товара, или целой территориальной единицы (жилого дома или квартала);
5. комбинированный (ступенчатый) отбор может сочетать в себе сразу несколько способов отбора (например, стратифицированный и случайный или случайный и механический); такая выборка называется комбинированной .
Виды отбора
По виду различаются индивидуальный, групповой и комбинированный отбор. При индивидуальном отборе в выборочную совокупность отбираются отдельные единицы генеральной совокупности, при групповом отборе — качественно однородные группы (серии) единиц, а комбинированный отбор предполагает сочетание первого и второго видов.
По методу отбора различают повторную и бесповторную выборку.
Бесповторным называется отбор, при котором попавшая в выборку единица не возвращается в исходную совокупность и в дальнейшем выборе не участвует; при этом численность единиц генеральной совокупности N сокращается в процессе отбора. При повторном отборе попавшая в выборку единица после регистрации возвращается в генеральную совокупность и таким образом сохраняет равную возможность наряду с другими единицами быть использованной в дальнейшей процедуре отбора; при этом численность единиц генеральной совокупности N остается неизменной (метод в социально-экономических исследованиях применяется редко). Однако, при большом N (N → ∞) формулы для бесповторного отбора приближаются к аналогичным для повторного отбора и практически чаще используются последние (N = const ).
Основные характеристики параметров генеральной и выборочной совокупности
В основе статистических выводов проведенного исследования лежит распределение случайной величины , наблюдаемые же значения (х 1 , х 2 , … , х n) называются реализациями случайной величины Х (n — объем выборки). Распределение случайной величины в генеральной совокупности носит теоретический, идеальный характер, а ее выборочный аналог является эмпирическим распределением. Некоторые теоретические распределения заданы аналитически, т.е. их параметры определяют значение функции распределения в каждой точке пространства возможных значений случайной величины . Для выборки же функцию распределения определить трудно, а иногда невозможно, поэтому параметры оценивают по эмпирическим данным, а затем их подставляют в аналитическое выражение, описывающее теоретическое распределение. При этом предположение (или гипотеза ) о виде распределения может быть как статистически верным, так и ошибочным. Но в любом случае восстановленное по выборке эмпирическое распределение лишь грубо характеризует истинное. Важнейшими параметрами распределений являются математическое ожидание и дисперсия .
По своей природе распределения бывают непрерывными и дискретными . Наиболее известным непрерывным распределением является нормальное . Выборочными аналогами параметров идля него являются: среднее значение и эмпирическая дисперсия . Среди дискретных в социально-экономических исследованиях наиболее часто применяется альтернативное (дихотомическое) распределение. Параметр математического ожидания этого распределения выражает относительную величину (или долю ) единиц совокупности, которые обладают изучаемым признаком (она обозначена буквой ); доля совокупности, не обладающая этим признаком, обозначается буквой q (q = 1 — p) . Дисперсия же альтернативного распределения также имеет эмпирический аналог .
В зависимости от вида распределения и от способа отбора единиц совокупности по-разному вычисляются характеристики параметров распределения. Основные из них для теоретического и эмпирического распределений приведены в табл. 9.1.
Долей выборки k n называется отношение числа единиц выборочной совокупности к числу единиц генеральной совокупности:
k n = n/N .
Выборочная доля w — это отношение единиц, обладающих изучаемым признаком x к объему выборки n :
w = n n /n .
Пример. В партии товара, содержащей 1000 ед., при 5% выборке доля выборки k n в абсолютной величине составляет 50 ед. (n = N*0,05); если же в этой выборке обнаружено 2 бракованных изделия, то выборочная доля брака w составит 0,04 (w = 2/50 = 0,04 или 4%).
Так как выборочная совокупность отлична от генеральной, то возникают ошибки выборки .
Таблица 9.1 Основные параметры генеральной и выборочной совокупностей
Ошибки выборки
При любом (сплошном и выборочном) могут встретиться ошибки двух видов: регистрации и репрезентативности. Ошибки регистрации могут иметь случайный и систематический характер. Случайные ошибки складываются из множества различных неконтролируемых причин, носят непреднамеренный характер и обычно по совокупности уравновешивают друг друга (например, изменения показателей прибора при температурных колебаниях в помещении).
Систематические ошибки тенденциозны, так как нарушают правила отбора объектов в выборку (например, отклонения в измерениях при изменении настройки измерительного прибора).
Пример. Для оценки социального положения населения в городе предусмотрено обследовать 25% семей. Если при этом выбор каждой четвертой квартиры основан на ее номере, то существует опасность отобрать все квартиры только одного типа (например, однокомнатные), что обеспечит систематическую ошибку и исказит результаты; выбор же номера квартиры по жребию более предпочтителен, так как ошибка будет случайной.
Ошибки репрезентативности присущи только выборочному наблюдению, их невозможно избежать и они возникают в результате того, что выборочная совокупность не полностью воспроизводит генеральную. Значения показателей, получаемых по выборке, отличаются от показателей этих же величин в генеральной совокупности (или получаемых при сплошном наблюдении).
Ошибка выборочного наблюдения есть разность между значением параметра в генеральной совокупности и ее выборочным значением. Для среднего значения количественного признака она равна: , а для доли (альтернативного признака) — .
Ошибки выборки свойственны только выборочным наблюдениям. Чем больше эти ошибки, тем больше эмпирическое распределение отличается от теоретического. Параметры эмпирического распределения и являются случайными величинами, следовательно, ошибки выборки также являются случайными величинами, могут принимать для разных выборок разные значения и поэтому принято вычислять среднюю ошибку .
Средняя ошибка выборки есть величина , выражающая среднее квадратическое отклонение выборочной средней от математического ожидания. Эта величина при соблюдении принципа случайного отбора зависит прежде всего от объема выборки и от степени варьирования признака: чем больше и чем меньше вариация признака (следовательно, и значение ), тем меньше величина средней ошибки выборки . Соотношение между дисперсиями генеральной и выборочной совокупностей выражается формулой:
т.е. при достаточно больших можно считать, что . Средняя ошибка выборки показывает возможные отклонения параметра выборочной совокупности от параметра генеральной. В табл. 9.2 приведены выражения для вычисления средней ошибки выборки при разных методах организации наблюдения.
Таблица 9.2 Средняя ошибка (m) выборочных средней и доли для разных видов выборки
Где - средняя из внутригрупповых выборочных дисперсий для непрерывного признака;
Средняя из внутригрупповых дисперсий доли;
— число отобранных серий, — общее число серий;
 ,
,
где — средняя -й серии;
— общая средняя по всей выборочной совокупности для непрерывного признака;
 ,
,
где — доля признака в -й серии;
— общая доля признака по всей выборочной совокупности.
Однако о величине средней ошибки можно судить лишь с определенной, вероятностью Р (Р ≤ 1). Ляпунов А.М. доказал, что распределение выборочных средних , a следовательно, и их отклонений от генеральной средней, при достаточно большом числе приближенно подчиняется нормальному закону распределения при условии, что генеральная совокупность обладает конечной средней и ограниченной дисперсией.
Математически это утверждение для средней выражается в виде:

а для доли выражение (1) примет вид:
где  -
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.
-
есть предельная ошибка выборки
, которая кратна величине средней ошибки выборки ,
а коэффициент кратности — есть критерий Стьюдента ("коэффициент доверия"), предложенный У.С. Госсетом (псевдоним "Student"); значения для разного объема выборки хранятся в специальной таблице.

Следовательно, выражение (3) может быть прочитано так: с вероятностью Р = 0,683 (68,3%) можно утверждать, что разность между выборочной и генеральной средней не превысит одной величины средней ошибки m (t = 1) , с вероятностью Р = 0,954 (95,4%) — что она не превысит величины двух средних ошибок m (t = 2) , с вероятностью Р = 0,997 (99,7%) — не превысит трех значений m (t = 3) . Таким образом, вероятность того, что эта разность превысит трехкратную величину средней ошибки определяет уровень ошибки и составляет не более 0,3% .
В табл. 9.3 приведены формулы для вычисления предельной ошибки выборки.
Таблица 9.3 Предельная ошибка (D) выборки для средней и доли (р) для разных видов выборочного наблюдения
Распространение выборочных результатов на генеральную совокупность
Конечной целью выборочного наблюдения является характеристика генеральной совокупности. При малых объемах выборки эмпирические оценки параметров ( и ) могут существенно отклоняться от их истинных значений ( и ). Поэтому возникает необходимость установить границы, в пределах которых для выборочных значений параметров ( и ) лежат истинные значения ( и ).
Доверительным интервалом какого-либо параметра θгенеральной совокупности называется случайная область значений этого параметра, которая с вероятностью близкой к 1 (надежностью ) содержит истинное значение этого параметра.
Предельная ошибка выборки Δ позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы , которые равны:
Нижняя граница доверительного интервала получена путем вычитания предельной ошибки из выборочного среднего (доли), а верхняя — путем ее добавления.
Доверительный интервал для средней использует предельную ошибку выборки и для заданного уровня достоверности определяется по формуле:
Это означает, что с заданной вероятностью Р
, которая называется доверительным уровнем и однозначно определяется значением t
, можно утверждать, что истинное значение средней лежит в пределах от ![]() ,а истинное значение доли — в пределах от
,а истинное значение доли — в пределах от
При расчете доверительного интервала для трех стандартных доверительных уровней Р = 95%, Р = 99% и Р = 99,9% значение выбирается по . Приложения в зависимости от числа степеней свободы . Если объем выборки достаточно велик, то соответствующие этим вероятностям значения t равны: 1,96, 2,58 и 3,29 . Таким образом, предельная ошибка выборки позволяет определить предельные значения характеристик генеральной совокупности и их доверительные интервалы:
Распространение результатов выборочного наблюдения на генеральную совокупность в социально-экономических исследованиях имеет свои особенности, так как требует полноты представительности всех ее типов и групп. Основой для возможности такого распространения является расчет относительной ошибки :

где Δ % - относительная предельная ошибка выборки; , .
Существуют два основных метода распространения выборочного наблюдения на генеральную совокупность: прямой пересчет и способ коэффициентов .
Сущность прямого пересчета заключается в умножении выборочного среднего значения!!\overline{x} на объем генеральной совокупности .
Пример . Пусть среднее число детей ясельного возраста в городе оценено выборочным методом и составило человека. Если в городе 1000 молодых семей, то число необходимых мест в муниципальных детских яслях получают умножением этой средней на численность генеральной совокупности N = 1000, т.е. составит 1200 мест.
Способ коэффициентов целесообразно использовать в случае, когда выборочное наблюдение проводится с целью уточнения данных сплошного наблюдения.
При этом используют формулу:
где все переменные — это численность совокупности:
Необходимый объем выборки
Таблица 9.4 Необходимый объем (n) выборки для разных видов организации выборочного наблюдения
При планировании выборочного наблюдения с заранее заданным значением допустимой ошибки выборки необходимо правильно оценить требуемый объем выборки . Этот объем может быть определен на основе допустимой ошибки при выборочном наблюдении исходя из заданной вероятности , гарантирующей допустимую величину уровня ошибки (с учетом способа организации наблюдения). Формулы для определения необходимой численности выборки n легко получить непосредственно из формул предельной ошибки выборки. Так, из выражения для предельной ошибки:
непосредственно определяется объем выборки n :
Эта формула показывает, что с уменьшением предельной ошибки выборки Δ существенно увеличивается требуемый объем выборки , который пропорционален дисперсии и квадрату критерия Стьюдента .
Для конкретного способа организации наблюдения требуемый объем выборки вычисляется согласно формулам, приведенным в табл. 9.4.
Практические примеры расчета
Пример 1. Вычисление среднего значения и доверительного интервала для непрерывного количественного признака.
Для оценки скорости расчета с кредиторами в банке проведена случайная выборка 10 платежных документов. Их значения оказались равными (в днях): 10; 3; 15; 15; 22; 7; 8; 1; 19; 20.
Необходимо с вероятностью Р = 0,954 определить предельную ошибку Δ выборочной средней и доверительные пределы среднего времени расчетов.
Решение. Среднее значение вычисляется по формуле из табл. 9.1 для выборочной совокупности
![]()
Дисперсия вычисляется по формуле из табл. 9.1.
![]()
Средняя квадратическая погрешность дня.
Ошибка средней вычисляется по формуле:
![]()
т.е. среднее значение равно x ± m = 12,0 ± 2,3 дней .
Достоверность среднего составила
![]()
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, и для Р = 0,954 уровня достоверности.
Таким образом, среднее значение равно `x ± D = `x ± 2m = 12,0 ± 4,6, т.е. его истинное значение лежит в пределах от 7,4 до16,6 дней.
Использование таблицы Стьюдента. Приложения позволяет заключить, что для n = 10 — 1 = 9 степеней свободы полученное значение достоверно с уровнем значимости a £ 0,001, т.е. полученное значение среднего достоверно отличается от 0.
Пример 2. Оценка вероятности (генеральной доли) р.
При механическом выборочном способе обследования социального положения 1000 семей выявлено, что доля малообеспеченных семей составила w = 0,3 (30%) (выборка была 2% , т.е. n/N = 0,02 ). Необходимо с уровнем достоверности р = 0,997 определить показатель р малообеспеченных семей во всем регионе.
Решение. По представленным значениям функции Ф(t) найдем для заданного уровня достоверности Р = 0,997 значение t = 3 (см. формулу 3). Предельную ошибку доли w определим по формуле из табл. 9.3 для бесповторного отбора (механическая выборка всегда является бесповторной):
Предельная относительная ошибка выборки в % составит:
Вероятность (генеральная доля) малообеспеченных семей в регионе составит р=w±Δ w , а доверительные пределы р вычисляются исходя из двойного неравенства:
w — Δ w ≤ p ≤ w — Δ w , т.е. истинное значение р лежит в пределах:
0,3 — 0,014 < p <0,3 + 0,014, а именно от 28,6% до 31,4%.
Таким образом, с вероятностью 0,997 можно утверждать, что доля малообеспеченных семей среди всех семей региона составляет от 28,6% до 31,4%.
Пример 3. Вычисление среднего значения и доверительного интервала для дискретного признака, заданного интервальным рядом.
В табл. 9.5. задано распределение заявок на изготовление заказов по срокам их выполнения предприятием.
Таблица 9.5 Распределение наблюдений по срокам появленияРешение. Средний срок выполнения заявок вычисляется по формуле:
Средний срок составит:
= (3*20 + 9*80 + 24*60 + 48*20 + 72*20)/200 = 23,1 мес.
Тот же ответ получим, если используем данные о р i из предпоследней колонки табл. 9.5, используя формулу:
Заметим, что середина интервала для последней градации находится путем искусственного ее дополнения шириной интервала предыдущей градации равной 60 — 36 = 24 мес.
Дисперсия вычисляется по формуле
![]()
где х i - середина интервального ряда.
Следовательно!!\sigma = \frac {20^2 + 14^2 + 1 + 25^2 + 49^2}{4}, а средняя квадратическая погрешность .
Ошибка средней вычисляется по формуле мес., т.е. среднее значение равно!!\overline{x} ± m = 23,1 ± 13,4.
Предельную ошибку вычислим по формуле из табл. 9.3 для повторного отбора, так как численность генеральной совокупности неизвестна, для 0,954 уровня достоверности:
Таким образом, среднее значение равно:
т.е. его истинное значение лежит в пределах от 0 до 50 мес.
Пример 4. Для определения скорости расчетов с кредиторами N = 500 предприятий корпорации в коммерческом банке необходимо провести выборочное исследование методом случайного бесповторного отбора. Определить необходимый объем выборки n, чтобы с вероятностью Р = 0,954 ошибка среднего значения выборки не превышала 3-х дней, если пробные оценки показали, что среднее квадратическое отклонение s составило 10 дней.
Решение . Для определения числа необходимых исследований n воспользуемся формулой для бесповторного отбора из табл. 9.4:

В ней значение t определяется из для уровня достоверности Р = 0,954. Оно равно 2. Среднее квадратическое значение s = 10, объем генеральной совокупности N = 500, а предельная ошибка среднего значения Δ x = 3. Подставляя эти значения в формулу, получим:
![]()
т.е. выборку достаточно составить из 41 предприятия, чтобы оценить требуемый параметр — скорость расчетов с кредиторами.
Приведенная ниже формула для расчета объема выборки используется в тех случаях, когда опрашиваемым (респондентам) задается только один вопрос, на который существует только два варианта ответа. Например, «Да» и «Нет»; «Пользуюсь» и «Не пользуюсь». Конечно, данную формулу можно применять только при проведении простейших исследований. Если Вам нужно определить объем выборки при проведении более масштабных исследований, например анкетирования, то следует использовать другие формулы.
Простая формула для расчета объема выборки

где: n – объем выборки;
z – нормированное отклонение, определяемое исходя из выбранного уровня доверительности. Этот показатель характеризует возможность, вероятность попадания ответов в специальный - доверительный интервал. На практике уровень доверительности часто принимают за 95% или 99%. Тогда значения z будут соответственно 1,96 и 2,58;
p – вариация для выборки, в долях. По сути, p - это вероятность того, что респонденты выберут той или иной вариант ответа. Допустим, если мы считаем, что четверть опрашиваемых выберут ответ «Да», то p будет равно 25%, то есть p = 0,25;
q = (1 – p);
e – допустимая ошибка, в долях.
Пример расчета объема выборки
Компания планирует провести социологическое исследование с целью выявить долю курящих лиц в населении города. Для этого сотрудники компании будут задавать прохожим один вопрос: «Вы курите?». Возможных вариантов ответа, таким образом, только два: «Да» и «Нет».
Объем выборки в этом случае рассчитывается следующим образом. Уровень доверительности принимается за 95%, тогда нормированное отклонение z = 1,96 . Вариацию принимаем за 50%, то есть условно считаем, что половина респондентов может ответить на вопрос о том, курят ли они - «Да». Тогда p = 0,5 . Отсюда находим q = 1 – p = 1 – 0,5 = 0,5 . Допустимую ошибку выборки принимаем за 10%, то есть e = 0,1 .
Подставляем эти данные в формулу и считаем:

Получаем объем выборки n = 96 человек .
Область применения данной формулы
При проведении простых исследований, когда нужно получить ответ всего на один простой вопрос. При этом шкала ответов, как правило, дихотомического характера. То есть предлагаются (или подразумеваются) варианты ответов по типу «Да» - «Нет», «Черное» - «Белое», и т.д.
Особенности данной формулы расчета объема выборки
Галяутдинов Р.Р.
© Копирование материала допустимо только при указании прямой гиперссылки на